
How Amazon Improved Graph-based Similarity Search by 60%[Technique Tuesdays]
Amazon’s Amazing Universal Graph Traversal Algorithm

Hey, it’s your favorite cult leader here 🦹♂️🦹♂️
On Tuesdays, I will cover problem-solving techniques that show up in software engineering, computer science, and Leetcode Style Questions📚📚📝📝.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly. You can use the following for an email template.
PS- We follow a “pay what you can” model, which allows you to support within your means, and support my mission of providing high-quality technical education to everyone for less than the price of a cup of coffee. Check out this post for more details and to find a plan that works for you.
As I’ve stated many times (especially on my primary newsletter, AI Made Simple)- I really like the Amazon Science blog. Of all the big-tech research groups- I find their work to be the most practical and direct. In this newsletter, I wanted to highlight their work with the publication- “FINGER: Fast inference for graph-based approximate nearest neighbor search” for two key reasons-
Firstly, their approach is universal and can be applied to any graph constructed (since the optimization is done on the search side, not on the graph construction). This is an underrated aspect of optimizations, and the universality of this algorithm makes testing it out very useful.
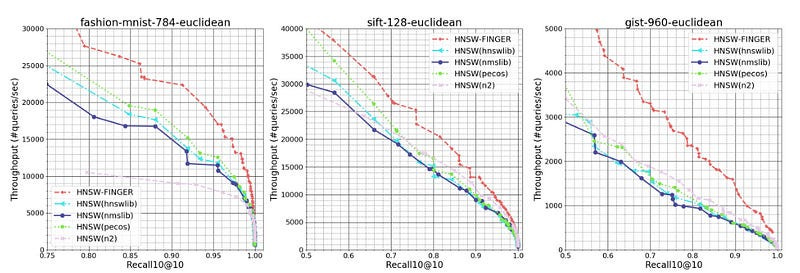
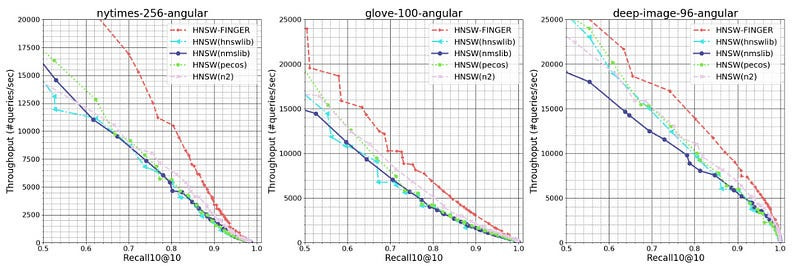
It hits some amazing numbers, “FINGER significantly outperforms existing acceleration approaches and conventional libraries by 20% to 60% across different benchmark datasets”
I’ve been experimenting with this idea for the Knowledge Graphing + GraphRAG for our work at IQIDIS AI, a very, very promising Legal AI platform that I’m working on building (more details here if you want to sign up for an early preview). While I don’t really have much to say right now (too many aspects to consider before I can make assessments of my own), I figured sharing this idea would be interesting to y’all, especially given how popular graphs are in building search/generation based products.
To evaluate our approach, we compared FINGER’s performance to that of three prior graph-based approximation methods on three different datasets. Across a range of different recall10@10 rates — or the rate at which the model found the query’s true nearest neighbor among its 10 top candidates — FINGER searched more efficiently than all of its predecessors. Sometimes the difference was quite dramatic — 50%, on one dataset, at the high recall rate of 98%, and almost 88% on another dataset, at the recall rate of 86%.
To understand how this (or any other powerful algorithm in general) works, it can be very helpful first to understand the high-level intuition for it. This can help us develop a deeper appreciation for the algorithmic design choices- and even think about how we might want to change an industry-standard solution into something that matches our requirements.
How FINGER works
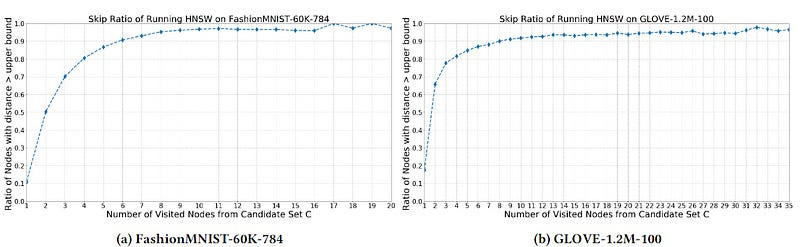
The secret to this performance lies in a fairly simple, but important insight- “when calculating the distance between the query and points that are farther away than any of the candidates currently on the list, an approximate distance measure will usually suffice.” Essentially, if I only want to consider top-5 similarity scores, then the exact distance of no. 6 and below is irrelevant to me. I can skip the heavy-duty distance computations in that case. I also don’t want to consider points that are further than my upper-bound distance. And as it turns out that after a while, “over 80 % of distance calculations are larger than the upper-bound. Using greedy graph search will inevitably waste a significant amount of computing time on non-influential operations.”

This leads Amazon to explore approximations for the distance measurement for the points further away. They finally settle on an approximation based on geometry + some vector algebra. Take a query vector, q, our current node whose neighbors are being explored, c, and one of c’s neighbors, d, whose distance from q we’ll compute next. “Both q and d can be represented as the sums of projections along c and “residual vectors” perpendicular to c. This is, essentially, to treat c as a basis vector of the space.”
The phrase “Basis Vector of the Space” might seem intimidating. Let’s take a teeny moment to understand what it is. I think it’s a super important idea, so I think it’s worth a brief detour-
Vector Spaces
Put simply, a Vector Space is the universe of a bunch of objects, which we call Vectors (it’s literally a space of Vectors). However, as with all good things in life, not every universe is good enough to get that special Vector Space Label. No, sir, we have standards here. For a space to be a vector space, you need to be able to:
Add vectors together: If you have two vectors, you should be able to combine them to get another vector in the same space.
Multiply vectors by numbers (scalars): You should be able to stretch, shrink, or even reverse the direction of a vector by multiplying it by a number.
If you're doing more formal math, it’s important to know the axioms around Vector Spaces, but we can skip them here (they are fairly simple, but a lot of High Level Math is getting very specific about definitions and concepts so that someone can else can figure out how our world changes when you decide to ditch those definitions and create new ones)-

Vectors Spaces are a deceptively simple idea that pop up in a lot of powerful areas for computation (this is one of the reasons why so many people make you learn Linear Algebra in Computer Science courses).
One of the ideas that go hand with VSs are Basis Vectors. In fact these are so tied in together that you already use Basis Vectors all the time w/o realizing it-
Basis Vectors
Let’s say we have a huge, thriving universe with lots of Vectors vectoring around. Now, within this vector space, how do we describe the location of a specific point or a specific vector? That’s where basis vectors come in. They provide the framework for navigating and describing any vector within the space.
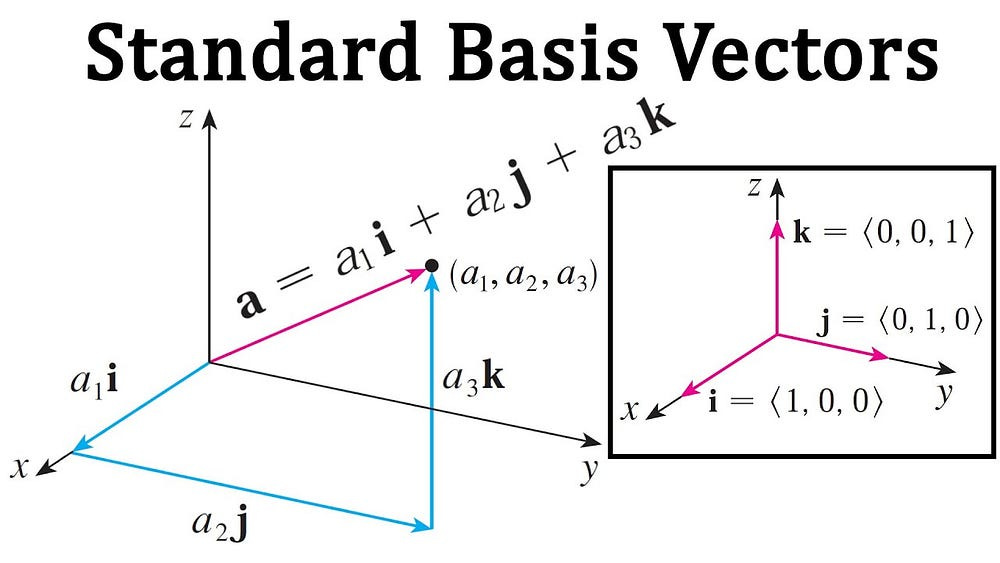
By breaking down a vector space into its fundamental building blocks, basis vectors make it easier to analyze and understand its properties. I do a lot of Linear Algebra, and read a lot lot more AI Research, and most of my reading/thinking is done in context of Basis Vectors, not the Spaces themselves.
Once again, we don’t just label any Vector that comes our way. Basis vectors are a special set of vectors that have two key properties:
Spanning: Given that we use them for navigation, basis vectors can be combined (through addition and scalar multiplication) to create any other vector in the space. They wouldn’t be any good for navigation in the Vector Space if they couldn’t reach every point in it.
Linear Independence: None of the basis vectors can be created by combining the others. If your basis vector is so unspecial that anything it gives you can be given to you by 1,2, or more (we don’t judge)- then it should be dropped. If any of you work in ML Engineering- this is one of the reasons why things like collinearity within features can be a problem. It’s also why the Complex Plane seems so interesting, but that’s for another day-

Back to the main topic- how Did Amazon Optimize their Graph Similarity searches. Let’s take a look into the math-
Understanding FINGER
As mentioned earlier, Amazon’s algorithm FINGER relies on Geometry and Linear Algebra. Let’s look into the idea in more detail here-
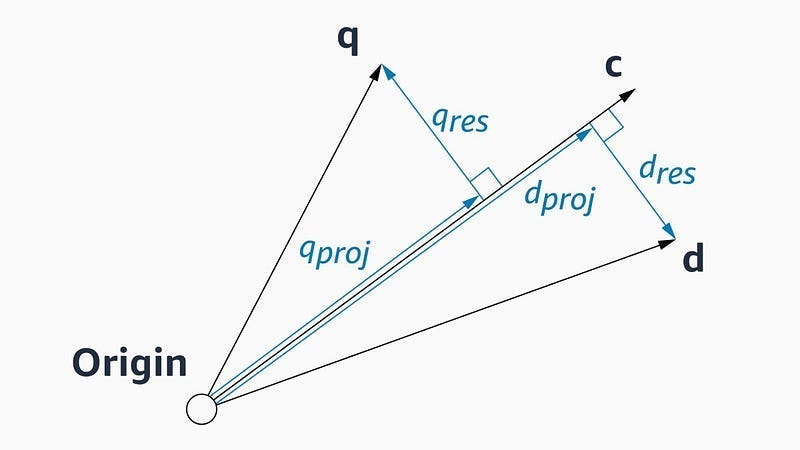
Firstly we know that if the algorithm is exploring neighbors of c, we have already calculated the distance between c and q. By combining that with some precomputations (a list of which can be found in Section B of the appendix), “estimating the distance between q and d is simply a matter of estimating the angle between their residual vectors.”
So how do we get that angle? For that we use the angles between the residual vectors of c’s immediate neighbors. “The idea is that, if q is close enough to c that c is worth exploring, then if q were part of the graph, it would probably be one of c’s nearest neighbors. Consequently, the relationships between the residual vectors of c’s other neighbors tell us something about the relationships between the residual vector of one of those neighbors — d — and q’s residual vector.”
There are some derivations, but I’m not going to touch upon them here b/c I really have nothing to add to them. Going over it here would be the newsletter equivalent of reading off the slides. If you want to check the math, check out Section 3.2 of the paper. For the rest of us let’s look at the FINGER algorithm.

Nothing too crazy, assuming you accept the math for the approximation. Aside from that, the big things to note would be line 14, where we switch to approximate distance computations to account for the observation that “starting from the 5th step of greedy graph search both experiments show more than 80% of data points will be larger than the current upper-bound.”
As mentioned earlier, this relatively simple approach leads to some very solid performance gains, “We can see that on the three selected datasets, HNSW-FINGER all performs 10%-15% better than HNSW-FINGER-RP. This results directly validates the proposed basis generation scheme is better than random Gaussian vectors. Also notice that HNSW-FINGER-RP actually performs better than HNSW(pecos) on all datasets. This further validates that the proposed approximation scheme is useful, and we could use different angle estimations methods to achieve good acceleration”
Pretty cool, huh? There’s a lot of nonsense going on about the end of AI, or that LLMs are hitting a wall. This is completely wrong. Research always runs into dead-ends, that doesn’t mean the research itself wasn’t meaningful. Sometimes the challenges/dead-ends for one branch of research catalyze a new direction. The costs/difficulty of Graph Search led to some very interesting work in graph optimizations, which will influence a lot of others. Ignore the fear/rage baiters, humanity and science are not slowing down anytime soon- and new(ish) developments like FINGER are great examples of this.
Thank you for reading and hope you have a wonderful day.
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription.
Many companies have a learning budget, and you can expense your subscription through that budget. You can use the following for an email template.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. You can share your testimonials over here.
I regularly share mini-updates on what I read on the Microblogging sites X(https://twitter.com/Machine01776819), Threads(https://www.threads.net/@iseethings404), and TikTok(https://www.tiktok.com/@devansh_ai_made_simple)- so follow me there if you’re interested in keeping up with my learnings.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819