
How to perform Data Collection & Labeling in 2026

Help me keep write high quality articles—
Enterprises are shifting capital away from model training and dumping it directly into data engineering. Building raw data infrastructure is no longer back-office plumbing; it is the core determinant of whether an AI system works in production or drains a budget.
If your data strategy begins and ends with scraping logs or generating generic synthetic labels, you are building an architectural dead end. Modern production AI relies on complex multi-component pipelines where failure happens silently at the seam. Teams that know how to architect continuous data supply chains, build deep telemetry, and defend against model collapse are commanding the highest premiums in the engineering market.
Understanding how to build, maintain, and protect this data supply chain is the single most valuable technical skill set of the next decade. If you cannot audit your data architecture, your production metrics will tank and you will have no way to diagnose why.
Data collection in 2026 isn’t “scrape some logs and clean them.” It’s building telemetry architecture that captures what’s actually happening in your system—not just what you think should be happening.
Modern ML systems are multi-component pipelines: retrieval, ranking, generation, tool calls, judge models, fallbacks. If you’re only logging model outputs, you’re blind to 80% of your failure modes. You need to capture user intent, retrieval context, ranking scores, tool sequences, agent reasoning artifacts, metadata, and failure categories. All of it. Because when something breaks (and it will), you need to know which component failed and under what conditions.
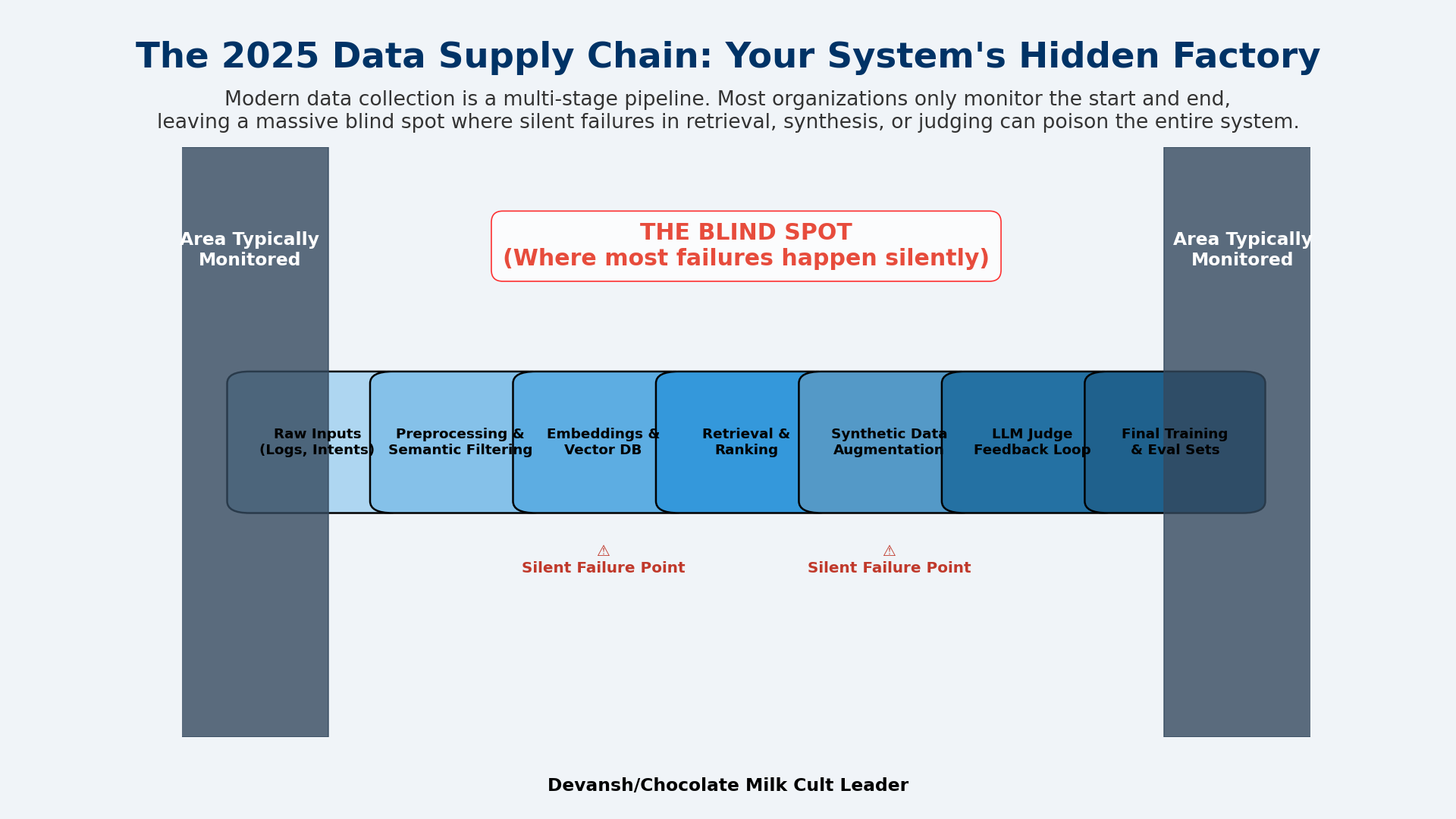
This creates a data supply chain: raw inputs → preprocessing → semantic filtering → embeddings → retrieval corpora → synthetic augmentation → judge-model feedback → evaluation sets → drift monitors → retraining triggers. Each stage can fail silently. Most organizations only instrument the first and last steps, then wonder why they can’t diagnose problems.
Synthetic Data is Now Default (With Caveats)
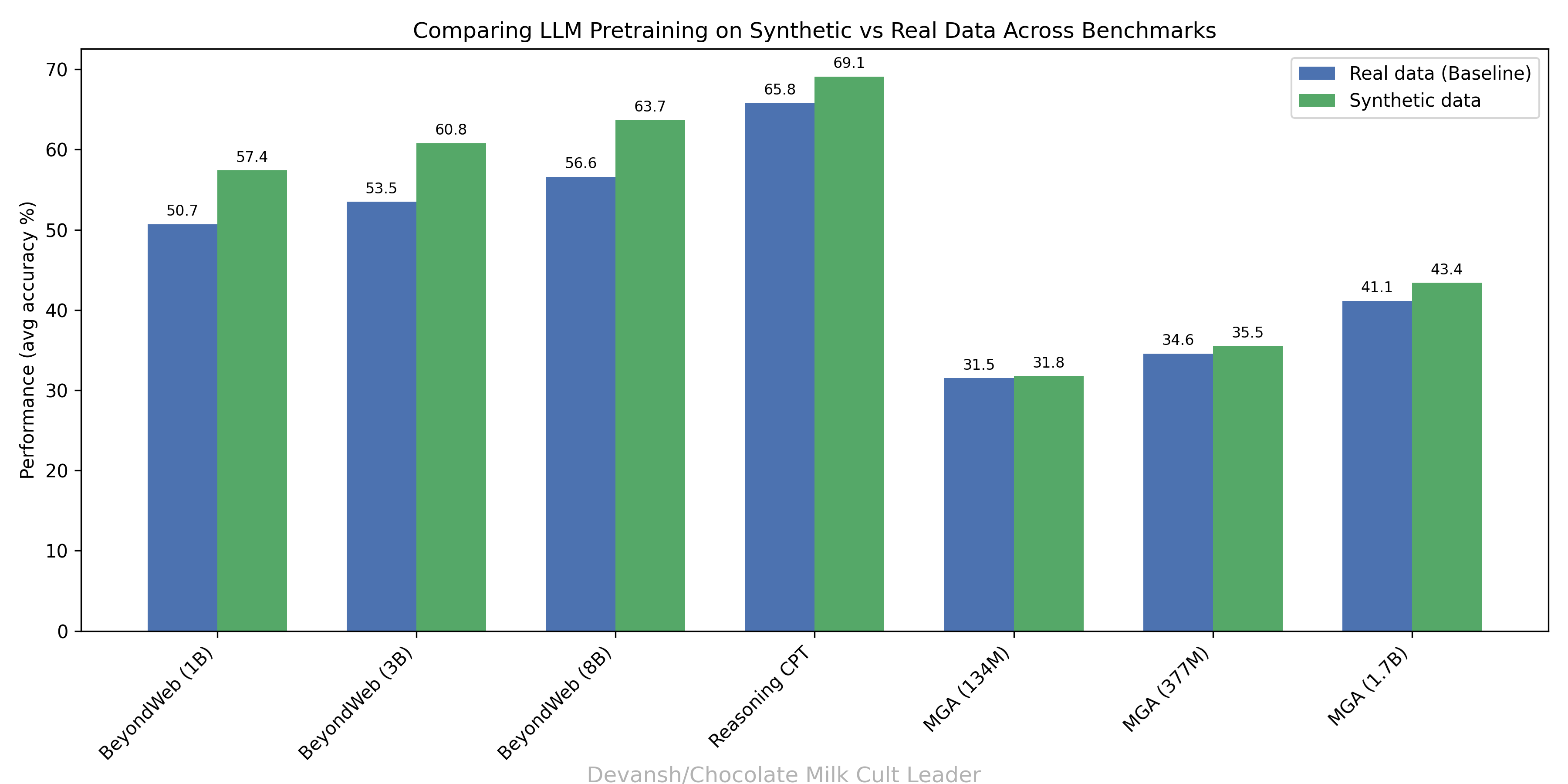
Synthetic labeling has become standard practice. LLM judges can generate training data faster and cheaper than human annotators, and for many tasks, they’re preferred by practitioners, especially over manually creating data directly.
“We conducted a mixed-method user study (N=24) to test the user experience and effectiveness of the tool. Synthesizing qualitative interview data, quantitative survey ratings, and behavioral logs, we found that most participants preferred the synthetic data generation tool over the manual approach. Using the tool, they were able to generate significantly more, longer, and syntactically diverse test cases without sacrificing data quality or incurring additional task load. The downstream impacts of the generated data on the evaluation criteria and their alignment with users’ expectations were as effective as human-crafted or real-world data.” -Source
But synthetic data carries hidden risks. Judge models show bias toward their related student models—a phenomenon called “preference leakage” that’s hard to detect. The judge model gives higher scores to outputs that match its own training distribution, creating a feedback loop where models optimize for their judge’s preferences instead of actual quality.
There is another risk, one well known, but for the wrong reason. Model Collapse is a well-known phenomenon where models trained on LLM generated data show worse performance. The explaination for this chart was given by the following image—
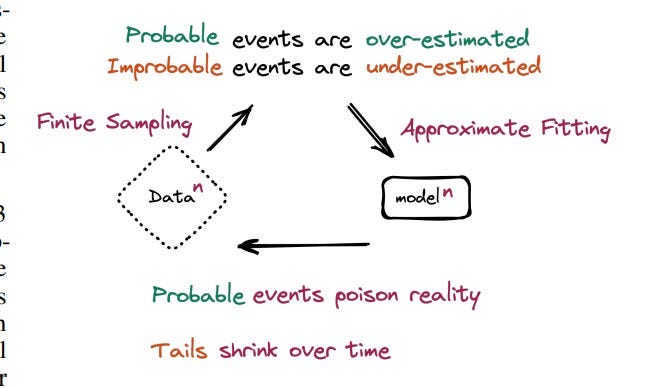
People see this and attribute the collapse to synthetic data. We call such people stupid.
The issue of model collapse is not the use of SD, but the loss of diversity. Therefore maintaining or improving the diversity of Synthetic Data will not only prevent collapse, it will improve performance.
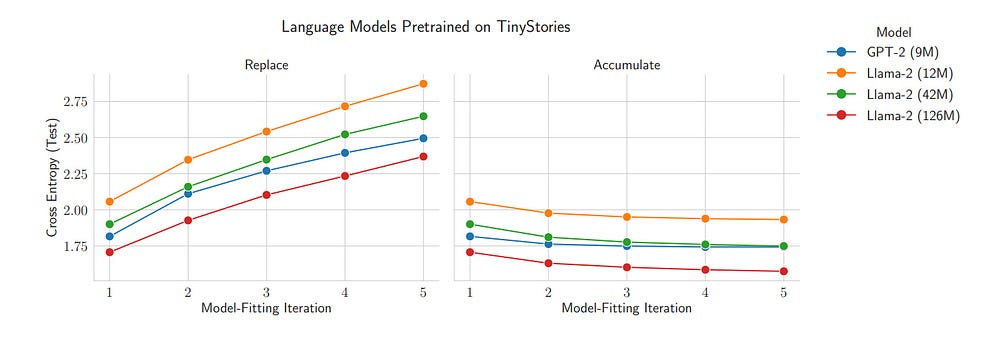
This is why multiple new age papers (like Google’s work with Quantum Chips) have matched/beaten state-of-the-art using only synthetic data. If you want to learn more about this, read this deep dive—

This means labeling in 2025 requires:
Human arbitration for edge cases and quality checks
Domain specialists to catch domain-specific failures the judge misses
Judge-model ensembles to reduce single-judge bias
Synthetic data quarantines (keeping synthetic and real data separate during evaluation)
Adversarial negative generation (intentionally creating bad examples the judge should reject)
Filtered corpora (create a strong base for pretraining).
Diversity checks (to ensure robustness/generalization).
You can’t just generate 100K labels with GPT-4 and call it done. You need infrastructure to validate, filter, audit, and continuously improve your synthetic pipeline. Otherwise, you’re training on contaminated data and won’t realize it until your production metrics tank.
The Real Cost is Maintenance, Not Collection
Most companies budget for initial data collection but not for data maintenance. Your training data decays. User behavior changes, product features evolve, edge cases accumulate, and your original labels become stale. A model trained on 2024 data will degrade on 2025 traffic—not because the model changed, but because the world did.
Data maintenance means:
Continuous re-labeling of high-impact samples
Active learning pipelines that flag uncertain predictions for human review
Drift detection on input distributions (not just model outputs)
Version control for datasets, not just models
Clear data lineage so you can trace any prediction back to its training examples
This is expensive. It’s also the only way to keep models accurate over time. Organizations that treat data as a one-time collection project will watch their models decay and won’t understand why.
Read more about what it takes to be an AI Engineer these days here:
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.
I regularly share mini-updates on what I read on the Microblogging sites X(https://twitter.com/Machine01776819), Threads(https://www.threads.net/@iseethings404), and TikTok(https://www.tiktok.com/@devansh_ai_made_simple)- so follow me there if you’re interested in keeping up with my learnings.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
https://machine-learning-made-simple.medium.com/
My YouTube: https://www.youtube.com/@ChocolateMilkCultLeader/
Reach out to me on LinkedIn. Let’s connect: https://www.linkedin.com/in/devansh-devansh-516004168/
My Instagram: https://www.instagram.com/iseethings404/
My Twitter: https://twitter.com/Machine01776819