
Memory Is the Biggest Problem in Software Right Now
Why modern systems keep slowing down, wasting compute, and breaking under state-heavy workloads

It takes time to create work that’s clear, independent, and genuinely useful. If you’ve found value in this newsletter, consider becoming a paid subscriber. It helps me dive deeper into research, reach more people, stay free from ads/hidden agendas, and supports my crippling chocolate milk addiction. We run on a “pay what you can” model—so if you believe in our mission of open soucring , there’s likely a plan that fits (over here).
Every subscription helps me stay independent, avoid clickbait, and focus on depth over noise, and I deeply appreciate everyone who chooses to support our cult.
PS – Supporting this work doesn’t have to come out of your pocket. If you read this as part of your professional development, you can use this email template to request reimbursement for your subscription.
Every month, the Chocolate Milk Cult reaches over a million Builders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission)- https://forms.gle/Pi1pGLuS1FmzXoLr6
For decades, progress in the tech industry has been framed as a compute problem. Faster CPUs, more cores, bigger clusters. But across databases, distributed systems, streaming pipelines, and now AI, a quieter constraint has been tightening: where state lives, how fast it can be accessed, and how often it has to be rebuilt.
This isn’t a new issue. Systems have always traded speed for capacity — fast memory close to the processor, slower storage further away. What is new is the scale and persistence of state modern software expects to hold. Long-running services, real-time analytics, personalization, and coordination-heavy workloads all strain that boundary. When state falls out of fast memory, systems don’t just slow down — they become brittle, unpredictable, and expensive to operate.
The rise of AI has compounded this pressure rather than created it. Agentic software, long contexts, and multi-step workflows dramatically increase how much state systems want to keep close at hand, turning an old architectural tradeoff into a first-order bottleneck. That shift is visible in how major infrastructure players are reorganizing their abstractions around memory and data movement, not just raw compute.
This piece is a deep dive into that underlying problem — how modern systems manage state, why the traditional memory-storage boundary is breaking down, and how those failures show up as latency spikes, wasted compute, and rising operational costs across the stack.
Executive Highlights (tl;dr of the article)
Modern software systems aren’t struggling because compute is scarce. They’re struggling because memory and state don’t scale cleanly anymore.
When working state fits in fast memory, systems are predictable. When it doesn’t, state gets pushed to slower storage or dropped and rebuilt later. Rebuilding that state isn’t free. For large workloads, reprocessing context can take hundreds of seconds per request and cost orders of magnitude more than reusing existing state.
In practice, a single cache miss on a large, state-heavy workload can turn a near-instant response into a tens-of-seconds delay. At scale, even a 20–30% recompute rate can translate into thousands of dollars per GPU per month in wasted compute, along with significant power draw.
As systems become more state-heavy — long-running services, coordination-heavy workflows, and AI-driven software — these costs compound. Latency spikes worsen, tail performance becomes unstable, and infrastructure efficiency drops even when average throughput looks fine.
The core tradeoff modern systems keep running into is simple: hold state close to compute, or redo the work that created it. Traditional memory hierarchies were never designed for how much state modern software now wants to keep alive.
Until state is treated as a first-class scaling problem, memory will remain the biggest hidden bottleneck in modern software.
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
1. The Bare Minimum Vocabulary
To make sure we’re speaking the same language, here is a list of the very important
Inference
Beyond the simple “model goes brrr to answer question”, your model.call() does two distinct things:
Prefill. It processes the entire input prompt at once. This is matrix multiplication heavy — exactly what GPUs are good at. More sequences in parallel = higher utilization.
Decode. It generates one token at a time. Each new token depends on the entire history of prior tokens. This phase is dominated by memory reads/writes rather than raw math.
If you treat prefill and decode the same, you either underutilize compute (during prefill) or blow up latency (during decode).

^^Inference Scaling is a very hot topic. We covered how you can cut your LLM costs 10–15x here.
State
The context required for the model to continue a thought. In a chatbot, state is the conversation history. In an agent, state is the plan, the tools, and the memory of previous steps. If you lose state, the model effectively gets amnesia.
Memory vs. Storage
This is a crucial technical distinction, especially since most common speech uses the terms interchangeably.
Memory (HBM/DRAM): The “Penthouse.” Extremely fast, extremely small, volatile (data vanishes when power cuts), and aggressively expensive (~$100/GB).
Storage (NVMe/SSD): The “Warehouse.” Slower, massive, persistent, and cheap (~$0.20/GB).
Historically, systems were designed with a hard boundary between the two. Memory was for computation; storage was for safekeeping.
KV Cache
The technical term for “State.” When a model reads your prompt, it calculates a massive set of Key-Value pairs representing the relationships between words.
Think of the KV Cache as the transcript of the model’s understanding. If you keep the transcript, the model can answer follow-up questions instantly. If you delete it, the model must re-read the entire book to understand the context again.
These 4 terms are enough to serve as a foundation for our exploration into the space. To understand why Weka’s work is worth studying, we must also understand how we’re currently handling memory and why that’s not working.
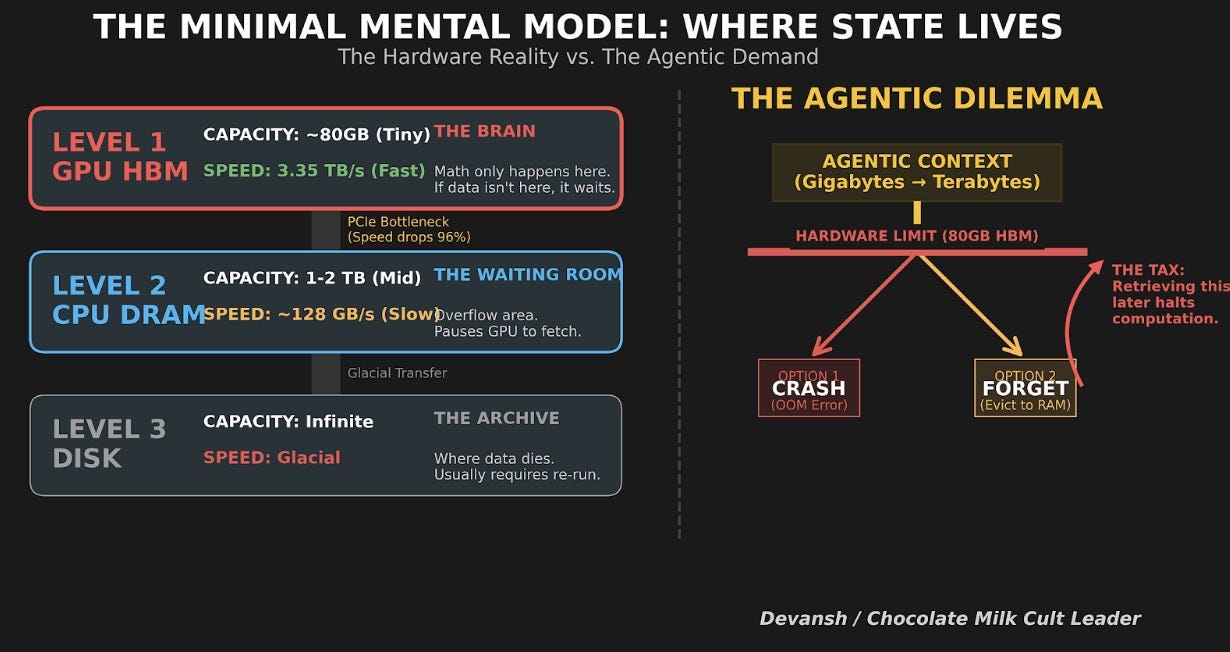
2. Where State Actually Lives (And Why This Is Starting to Fail)
An AI system’s state can live in a few places, each representing a fundamental tradeoff between speed and size. Visualizing this simple hierarchy is key to understanding the entire problem.
On the GPU (HBM): The fastest, closest, and smallest tier of memory. This is the ideal place for the model’s active working state.
In System Memory (DRAM): Slower and farther away from the GPU’s processors, but significantly larger.
On Network Storage (NVMe): The slowest of the three, but vastly larger and, crucially, persistent — it remembers even when the power is off.
When GPU memory fills up, state gets pushed to CPU memory. When CPU memory fills up, state gets pushed to storage or simply dropped. And when state gets dropped, the system has to regenerate it — which means redoing the work that created it in the first place. This is the only trade-off that matters at the infrastructure level: hold state, or redo work.
NVIDIA has formalized the memory tiers for AI factories. I expect this terminology to become more mainstream going forward so it is worth taking a second to make note of it:
G1 (GPU HBM) for hot, latency‑critical KV used in active generation
G2 (system RAM) for staging and buffering KV off HBM
G3 (local SSDs) for warm KV that is reused over shorter timescales
G4 (shared storage) for cold artifacts, history, and results that must be durable but are not on the immediate critical path
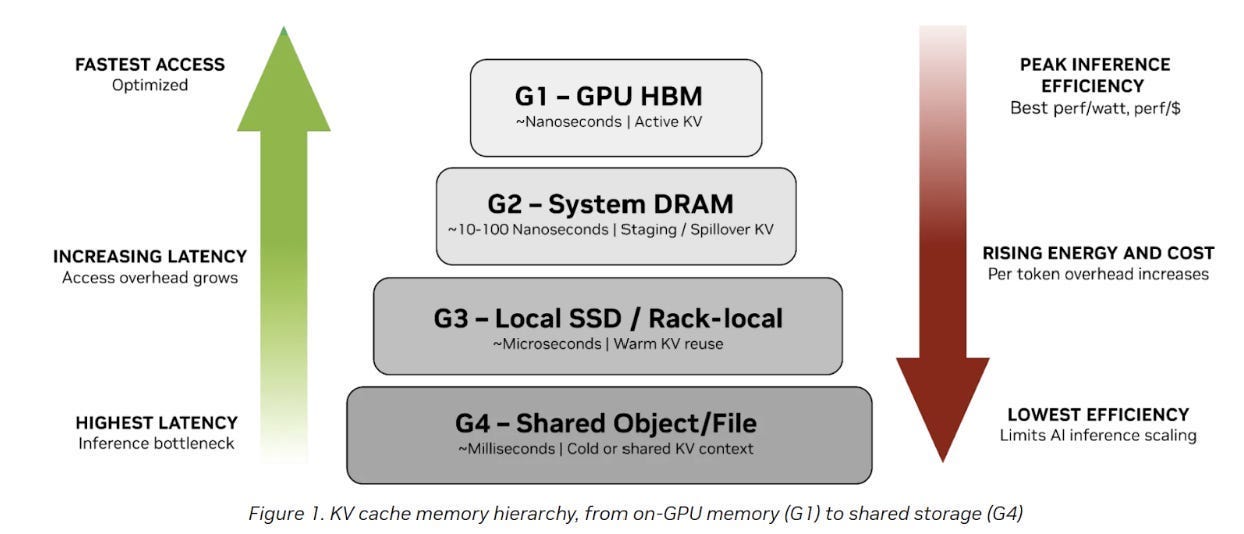
The key takeaway is that latency and efficiency are tightly coupled: as inference context moves away from the GPU, access latency increases, energy use and cost per token rise, and overall efficiency declines. This growing gap between performance-optimized memory and capacity-optimized storage is what forces AI infrastructure teams to rethink how growing KV cache context is placed, managed, and scaled across the system.
Agentic AI — multi-turn conversations, tool-using agents, persistent reasoning — keeps increasing how much state you want to hold. An agent coordinating a complex task might accumulate hundreds of thousands of tokens of context. A swarm of sub-agents multiplies that further.
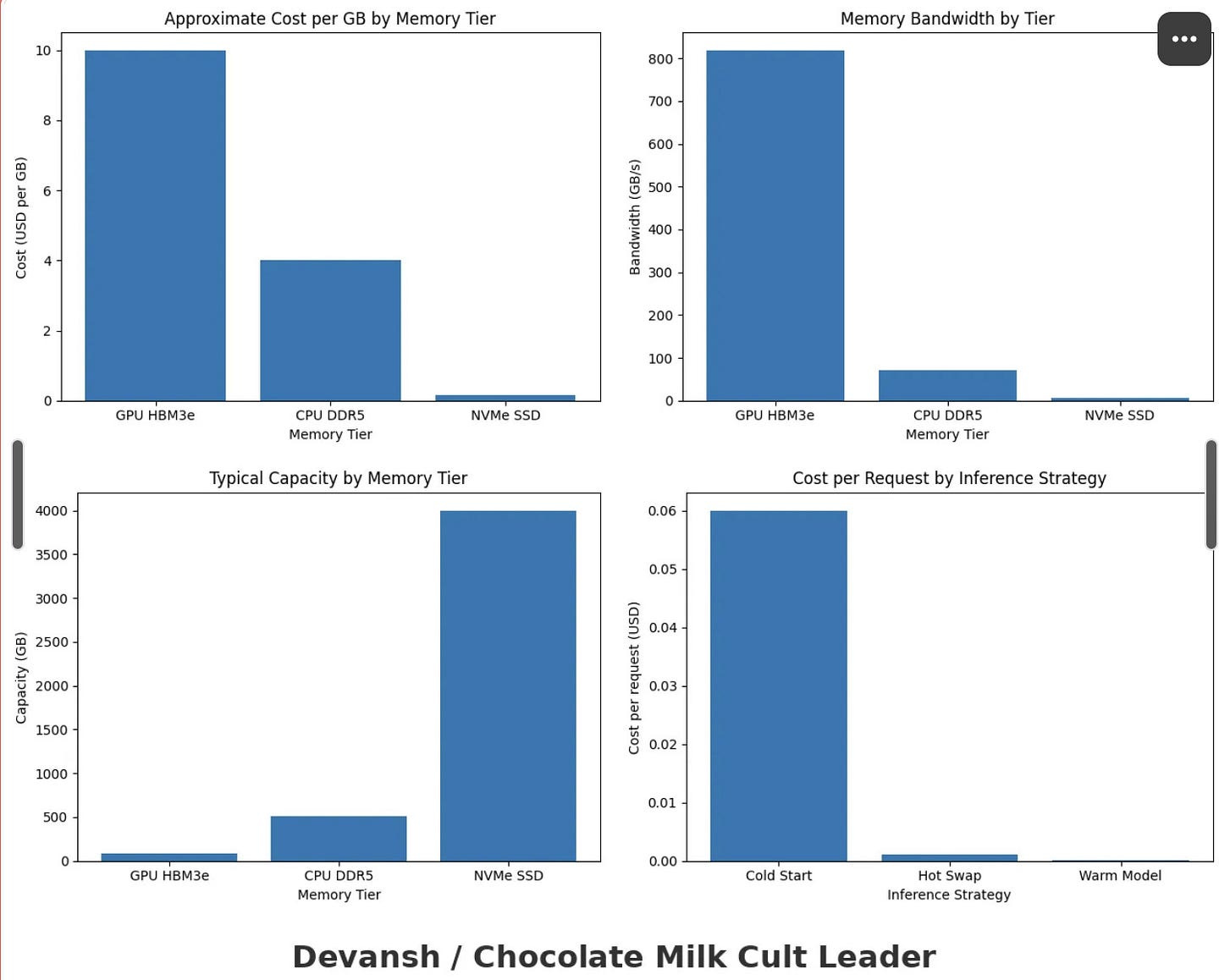
^^Running a cold start on a GPU (loading the model from scratch) costs roughly 160 s in TTFT — about $0.06 per request at $1.35/hour. Hot‑swapping (loading from CPU memory) takes ~2.9 s (≈$0.0011), and a warm model is near‑instant at ~0.17 s (≈$0.00006).
Hardware memory doesn’t scale to meet that demand. GPU memory is physically constrained. CPU memory is expensive and still volatile.
The question becomes: can storage be made fast enough to act like memory?
That’s the question WEKA is answering. Before we look at their solution, we need to understand why these failures show up the way they do, and how they translate directly into latency spikes and cost explosions. Let’s do that next.

3: Why Modern AI Breaks Old Assumptions
The breakdowns we just described aren’t theoretical. They surface in production systems in a few very specific, repeatable ways. Understanding these failure modes is important because each one has a clear performance signature and a clear economic cost.
3.1 The Recompute Tax
Imagine you’ve fallen behind on keeping up with an important email thread because you were too busy playing Age of Empires on company time. Now your dumbass needs to send a deliverable immediately b/c your Khoon-Ki-Pyaasi Daayan boss always ships you with last-minute work that he’ll take credit for. So you send a long prompt of the entire email chain + documents. The model processes it, building up KV cache as it goes. That processing (called “prefill”) is computationally expensive — it’s the phase where the model actually “reads” the input. Once prefill is done, the model generates its response using the cached state.
Now you ask a follow-up question. In an ideal system, the KV cache from the first turn is still available. The model only needs to process the new tokens, then continue generating.
But if the KV cache was evicted — because GPU memory filled up, or because the session was routed to a different server — the system has to redo the entire prefill. Every token of context, reprocessed. That’s the recompute tax.
The cost model:
Let’s define the variables:
C = GPU cost per hour
T_prefill = time to prefill a given context length
R = percentage of requests that trigger recompute (cache miss rate)
N = number of requests per hour
The wasted GPU cost per hour is:
Waste = C × (T_prefill / 3600) × R × N
C = $2.50/hour (H100)
T_prefill = 400 seconds (Llama 70B, 128k context) . (Production systems wouldn’t use single-GPU generations, but we’re doing this for simplicity’s sake. )
R = 30% (with sticky routing, no persistent cache)
N = 80 requests/hour (with batching)
Waste = $2.50 × (400 / 3600) × 0.30 × 80 = $2.50 × 0.111 × 0.30 × 80 = $6.67/hour per GPU = $4,800/month per GPU
And this scales superlinearly with context length. The 39.4-second prefill is for 128k tokens. As context windows push toward 1M tokens, prefill times grow proportionally. The recompute tax becomes the dominant cost.
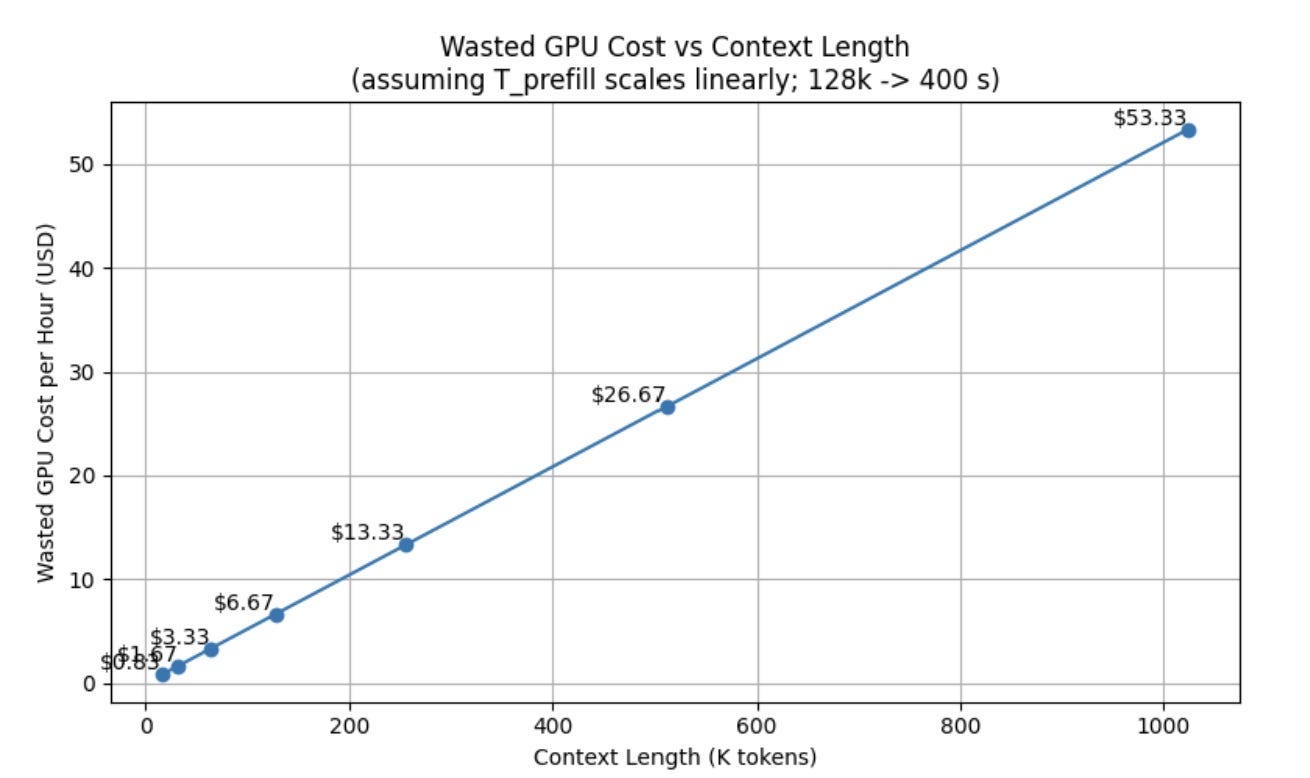
^^ Note this is increasing cost per hour, not total cost. More context → more breaks/context rot etc.
There is another constraint, harder than money: Power. Recomputing a KV cache burns peak GPU wattage (700W+ per H100) to produce heat, not value.
NVIDIA’s analysis shows that AMG delivers 5x better power efficiency than standard storage approaches. Why? Because fetching data from flash consumes a fraction of the energy required to re-run the matrix math to generate it. For data centers capped by the local power grid (where you physically cannot plug in more GPUs), WEKA isn’t just saving money — it’s trading “Hot Watts” (Compute) for “Cool Watts” (Flash), freeing up power budget to run more inference.
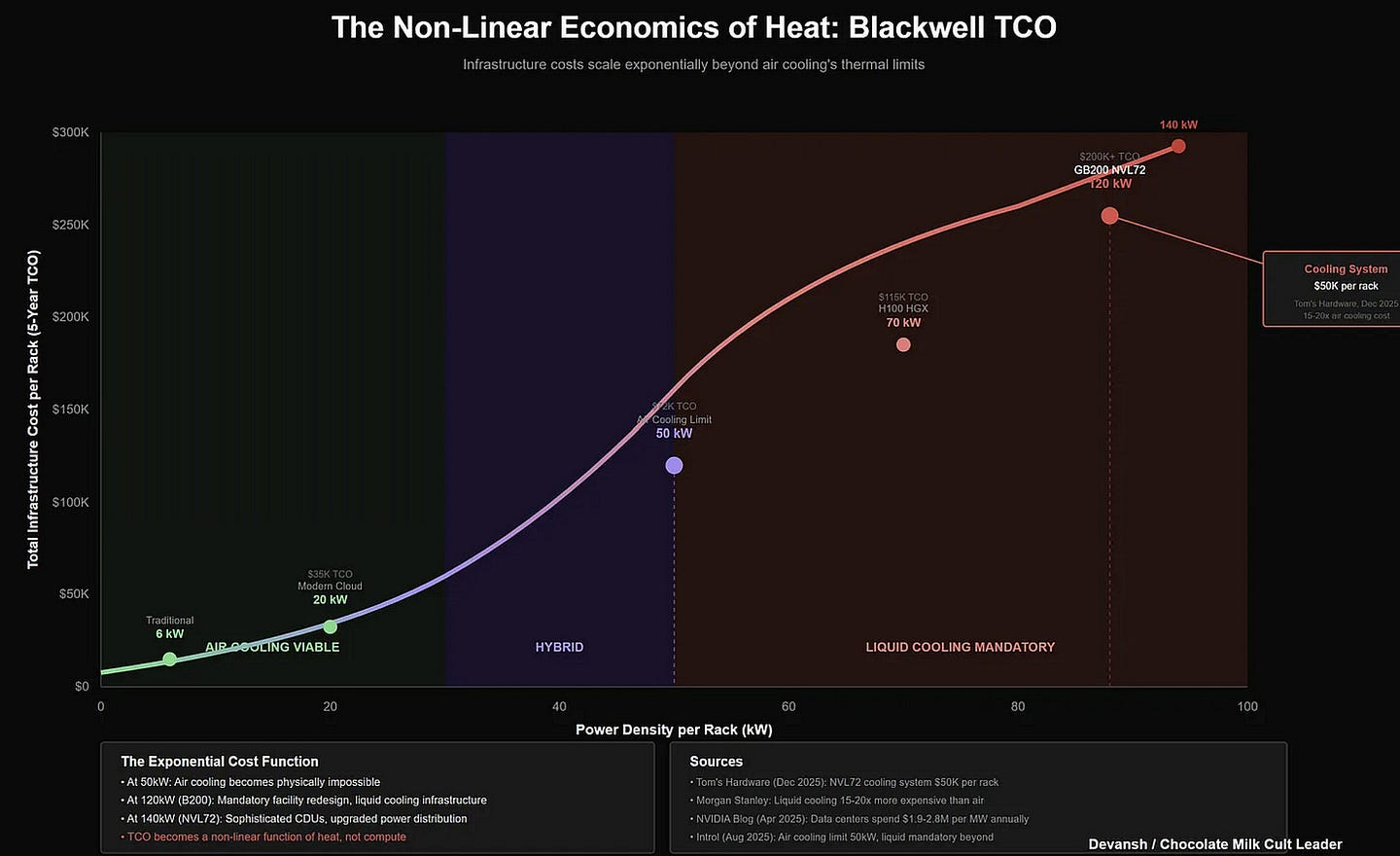
^^We broke down the costs of energy amd heat here.
3.2 GPU Starvation
GPUs are incredibly fast consumers of data. Traditional storage stacks (TCP/IP, Kernel context switches) are relatively slow suppliers. When the GPU finishes a batch and requests the next one, there is often a lag while the data navigates the OS bureaucracy.
During that lag, the GPU utilization drops to 0%.
If your data loading stack causes a 100ms delay every second, your $30,000 hardware is effectively running at 90% capacity. You have paid for 100 GPUs but are getting the output of 90.
3.3 Tail Latency Compounding
Most performance discussions focus on average latency. Real systems fail in the tail.
Recompute doesn’t slow everything down evenly. It creates latency cliffs:
one request returns instantly,
the next takes tens of seconds,
the next times out entirely.
In multi-turn systems, this is especially damaging. A delay early in a sequence compounds across every subsequent step. A few hundred milliseconds of additional latency at each step can turn a task that should take seconds into something that takes minutes.
This is why time-to-first-token (TTFT) matters more than raw throughput for interactive systems. Users don’t notice peak tokens per second; they notice pauses.
3.4 Metadata Storms
AI pipelines rarely deal with one 100TB file. They deal with ten million 10MB files (checkpoints, dataset shards, logs).
Every file on a storage system has data about the data, called metadata. This includes the file’s name, its size, its location, and permissions. While the data itself might be large, metadata operations are typically small, fast, and numerous.
Every time a GPU asks for a file, it hits the storage system’s Metadata Server. The server has to check permissions, look up the file location, and update the access time.
Unfortunately, when a 1,000-node training run starts, every node hits the server simultaneously. The bandwidth pipes are empty, but the server is deadlocked handling the index. The cluster sits idle, burning electricity, waiting for the filesystem to figure out where the data is.
(If your manager is smart, they will use this opportunity to get more budget and headcount, thereby increasing their “importance” to the organization. When you start looking into the stories, it’s crazy how many corporate incentives can be gamed to reward failure and punish efficiency).
The Requirements List
Any solution to these problems needs to:
Keep state without recompute: persistent, accessible KV cache that survives session migration and GPU memory pressure
Feed GPUs consistently: throughput that scales with cluster size without creating starvation
Handle metadata-heavy pipelines: no centralized chokepoint for file operations
Deliver predictable latency: low tail latency, not just low average latency
Scale without coordination bottlenecks: adding nodes should add capacity, not add contention
If you want to see how people are trying to solve this problem, we did a deep dive into Weka, one of the providers at the forefront of this problem over here. Check it out. You already have the background, so read from section 4.

Thank you for being here, and I hope you have a wonderful day.
Dev ❤
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.
I regularly share mini-updates on what I read on the Microblogging sites X(https://twitter.com/Machine01776819), Threads(https://www.threads.net/@iseethings404), and TikTok(https://www.tiktok.com/@devansh_ai_made_simple)- so follow me there if you’re interested in keeping up with my learnings.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
https://machine-learning-made-simple.medium.com/
My YouTube: https://www.youtube.com/@ChocolateMilkCultLeader/
Reach out to me on LinkedIn. Let’s connect: https://www.linkedin.com/in/devansh-devansh-516004168/
My Instagram: https://www.instagram.com/iseethings404/
My Twitter: https://twitter.com/Machine01776819
Didn't expect this! What if memory becomes true compute?
I think you have a typo in an approximate cost, perhaps an extra zero. $10 per gig seems in line with your chart showing GPU memory costs.
Memory (HBM/DRAM): The “Penthouse.” Extremely fast, extremely small, volatile (data vanishes when power cuts), and aggressively expensive (~$100/GB).