
Researchers Discover Possible Reason why Adversarial Perturbation Works

This was an interesting paper
I am very interested in the field of AI Robustness. As tech solutions scale and become more popular, we will see more people trying to exploit them. A popular example of that is spam email. Spam email often has many viruses and trojan embedded in a way that is imperceptible to us. Which causes problems.
People use Machine Learning to counter this (spam filters were originally built on the Naive Bayes Algorithm). Scammers try to get around this. This has caused an arms race between scammers and engineers.

Following is an example of Adversarial Learning, where we try to fool image classifiers(Youtube video introducing the concept here). Adversarial examples are inputs designed to fool ML models. How does this work? Take the image classifier above. It takes an image and returns a label with probabilities. Suppose we want a giraffe picture to output an elephant label. We will take the giraffe picture, and start tweaking the pixel data. We will continue to do so to minimize disagreement with the elephant picture. Eventually, we end up with a weird picture that has the giraffe picture as the base but looks like an elephant to the agent. This process is called Adversarial Perturbation. These perturbations are often invisible to humans, which is what makes them so dangerous.

“Adversarial Examples Are Not Bugs, They Are Features” by an MIT research team is a paper that seeks to answer why Adversarial Perturbation works. They discover that the predictive features of an image might be classified into two types, Robust and Non-Robust. The paper explores how Adversarial Disturbance affects each kind of feature. This article will go over some interesting discoveries in the paper.

Takeaways
Now that you guys understand the background about adversarial learning and why it’s important, here are some insights from the paper that will be useful in your machine learning journeys.
Robust vs Non-Robust Features

Robust features are simply useful features that remain useful after some kind of adversarial perturbation is applied. Non-robust features are features that were useful before the perturbation but now may even cause misclassification.

Robust Features Are (Might be) Enough
As somebody who advocates low-cost training (I’m a huge 80–20 guy) this is possibly the one takeaway that had me salivating the most. The authors of this paper did some interesting things. They used the original datasets to create 2 new datasets: 1) DR: A dataset constructed of the robust features. 2) DNR: Dataset of non-robust features.
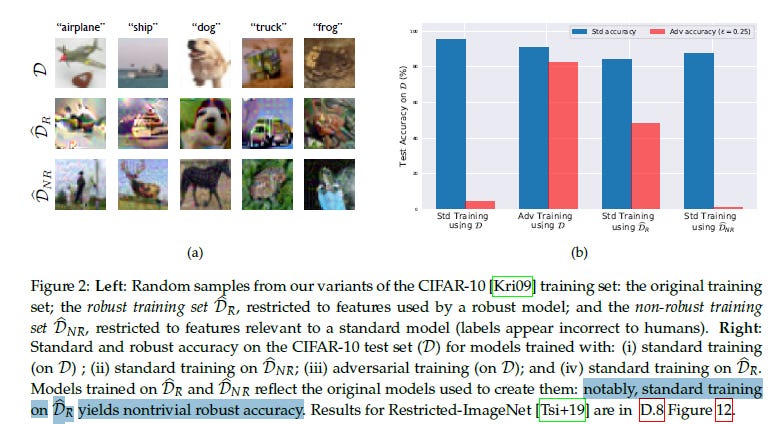
They found that training standard classifiers on the DR set provided good accuracy. Nothing too shocking, this was the definition of Robust Features. AND they had fantastic performance after adversarial perturbations were applied. Nothing too surprising. What got me was how well the robust dataset performed in normal training. Digging through the appendix we find this juicy table.

To quote the authors of this paper, “ The results (Figure 2b) indicate that the classifier learned using the new dataset attains good accuracy in both standard and adversarial settings.”To me, this presents an interesting solution. If your organization does not have the resources to invest in a lot of adversarial training/detection, an alternative might be to identify the robust features and train on them exclusively. This will protect you against adversarial input while providing good accuracy in normal use.

Adversarial Examples attack Non-Robust Features
This was the hypothesis of the paper. And the authors do a good job proving it. They point out that, “restricting the dataset to only contain features that are used by a robust model, standard training results in classifiers that are significantly more robust. This suggests that when training on the standard dataset, non-robust features take on a large role in the resulting learned classifier. Here we set out to show that this role is not merely incidental or due to finite-sample overfitting. In particular, we demonstrate that non-robust features alone suffice for standard generalization — i.e., a model trained solely on non-robust features can perform well on the standard test set.” In simple words, non-robust features are highly predictive and might even play a stronger role in the actual predictions.

This is where it gets interesting. The authors tested multiple architectures with adversarial examples and saw that they were all similarly vulnerable to them. This goes very well with their hypothesis. To quote them
Recall that, according to our main thesis, adversarial examples can arise as a result of perturbing well-generalizing, yet brittle features. Given that such features are inherent to the data distribution, different classifiers trained on independent samples from that distribution are likely to utilize similar non-robust features. Consequently, an adversarial example constructed by exploiting the non-robust features learned by one classifier will transfer to any other classifier utilizing these features in a similar manner.
Closing
This is quite an insightful paper. I’m intrigued by a few questions/extensions:
Testing this with non-binary datasets to see how well this approach can extend. More classes can make decision boundaries fuzzier so Robust datasets might not work as well (I still have hope).
Do all adversarial examples operate by attacking non-robust features, or is this a subset?
Let me know what you think. I would love to hear your thoughts on this paper.
If you liked this article, check out my other content. I post regularly on Medium, YouTube, Twitter, and Substack (all linked below). I focus on Artificial Intelligence, Machine Learning, Technology, and Software Development. If you’re preparing for coding interviews check out: Coding Interviews Made Simple.
For one-time support of my work following are my Venmo and Paypal. Any amount is appreciated and helps a lot:
Venmo: https://account.venmo.com/u/FNU-Devansh
Paypal: paypal.me/ISeeThings
Reach out to me
If that article got you interested in reaching out to me, then this section is for you. You can reach out to me on any of the platforms, or check out any of my other content. If you’d like to discuss tutoring, text me on LinkedIn, IG, or Twitter. If you’d like to support my work, use my free Robinhood referral link. We both get a free stock, and there is no risk to you. So not using it is just losing free money.
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
If you’re preparing for coding/technical interviews: https://codinginterviewsmadesimple.substack.com/
Get a free stock on Robinhood: https://join.robinhood.com/fnud75
Mlearning.ai Submission Suggestions
Researchers Discover Possible Reason why Adversarial Perturbation Works was originally published in MLearning.ai on Medium, where people are continuing the conversation by highlighting and responding to this story.