
[Solution]Problem 37: Word Search[Amazon]
Backtracking, Recursion, Strings, Graphs

This is going to be fun.
I can already feel your excitement, so I won’t waste time with an intro. Just remember, that this problem is very important. For your interviews.
Problem
Given an m x n grid of characters board and a string word, return true if word exists in the grid.
The word can be constructed from letters of sequentially adjacent cells, where adjacent cells are horizontally or vertically neighboring. The same letter cell may not be used more than once.
Example 1:
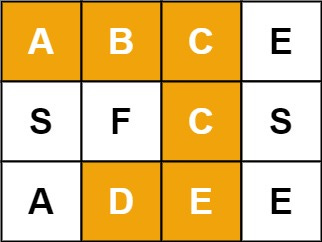
Input: board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCCED"
Output: true
Example 2:
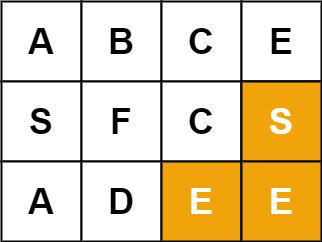
Input: board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "SEE"
Output: true
Example 3:

Input: board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCB"
Output: false
You can test your solution here

[FREE SUBS]To buy the solution for this problem, use any of the following links. The price is 3 USD. Once you send the payment, message me on IG, LinkedIn, Twitter, or by Email:
Venmo: https://account.venmo.com/u/FNU-Devansh
Paypal: paypal.me/ISeeThings
Or you can sign up for a Free Trial Below. Only 15 days left in this offer -
Step 1: Spotting the pattern
This problem is relatively straightforward to understand. We have a board and we want to identify whether the word exists on that board. A word exists if it can be created from letters in cells that are adjacent (in the cardinal directions), using only one cell at a time.

This is a very common setup for Graph problems. So common, that regular readers probably caught it immediately. I don’t want to spend too long on it. But let’s run through the Frameworks we have discussed as Sanity Checks.
Firstly, we will use this Graph Spotting discussed during a previous Math Monday. According to it, we can use a graph if we can view our system in the following way-
Nodes/Entities- Clearly, our cells match the definition of the cells to a T.
Edges/Relationships-Is there a valid between two cells? It’s obvious that two cells being adjacent make for a fairly clear relationship. It is also relevant to our problem.
Weighted(?)- There is no difference between two pairs of adjacent cells (aside from content possibly). Thus, we can use an unweighted graph.
If any part of this confuses you, go back and read through the post. It goes into the framework in great detail and shows where it would be effective. We also go through some examples to stress test our framework.
Step 2: Identifying the traversal algorithm
So we have a graph problem. The next step is to figure out how to traverse the graph. We have our usual suspects, so is there a way we can narrow things down? Let’s look at a few things-
We’re not really trying to find the shortest path (so the path-finding algorithms are not needed).
We will potentially have to visit every node in the graph. Thus, BFS might get very expensive in terms of Space.
This leaves DFS as our answer. To learn more about identifying the correct graph traversal algorithm, read How to Figure out the correct distance finding algorithm [Technique Tuesday] It’s got a really cool pun in there, which I am very proud of. And naturally, the content is top tier. But that’s true for all the content on this newsletter :)

Another observation that should be clear is that this problem will require backtracking. Thus as we implement our DFS, we want to add and remove our values in accordance with the backtracking process.
Step 3: Implementing our DFS
Next comes our DFS implementation. You can actually just write a vanilla DFS, and Leetcode will accept it. To those of you not comfortable with the DFS/Backtracking implementation, study this code in depth. It is what you need.
class Solution:
def exist(self, board: List[List[str]], word: str) -> bool:
n_r, n_c = len(board), len(board[0])
visited=set()
def dfs( idx, r, c):
if r<0 or r>=len(board) or c<0 or c>=len(board[0]):
return False
if board[r][c]!=word[idx] or (r,c) in visited:
return False
if idx == len(word)-1:
return True
visited.add((r,c))
for dr,dc in neighbors:
nr,nc = r+dr, c+dc
if dfs( idx+1, nr, nc):
return True
visited.remove((r,c)) # This node is not in our solution
return False # we did not find any words through this cell w/ combination given
neighbors = ((1,0), (-1,0), (0,1), (0,-1))
for r in range(len(board)):
for c in range(len(board[0])):
if dfs( 0, r,c):
return True
return False
We follow the backtracking SOP of adding a node to our visited set and removing it if we don’t hit a termination case. However, anybody can see that this solution is terrible. Running it on Leetcode, we see the terrible performance

However, by implementing some pruning and memory optimization we can reach our beast mode solution. It is going to be some work, but the performance speaks for itself.

Our pruning will not reduce the asymptotic complexity. It will however allow us to go through options quicker on average. We will also reduce our memory needs by getting rid of some unneeded extra space. I could get away by doing it because I solved the problem relatively quickly, so I had time.
Step 5: Optimize
There are various optimizations we can make. Firstly when it comes to space, there is no reason to use a visited set. In our case,we can directly mark the cells visited by changing the board. Since we always undo the change at the end for backtracking, this will not have any side effects. We want to use a string that we know isn’t part of the normal board. My goto is “.”.
The second step is to prune through some obvious cases. Here are the 4 that are simple to implement but change your performance-
Notice that the word can start in reverse. And the reverse of the word can come first. In such a case we want to check for the reverse of the word. We can infer which is more likely by tracking the counts of the nodes and comparing the counts of the first and last letters of our word.
If the count of any letter in our word is more than that letter’s occurrence on the board, we can return false.
Backtracking is expensive. Thus we want to reduce the number of times we try it. An easy reduction is to simply only call Backtracking when the letter at our cell matches the first letter in our word.
We can also immediately return false if the length of our word is more than the area of the grid (all letters on the board).
Combining these, we get the following code.
class Solution:
def exist(self, board: List[List[str]], word: str) -> bool:
n_r, n_c = len(board), len(board[0])
if(len(word)>n_r *n_c): #violates option 4
return False
# pruning option 1
count = Counter()
for i in range(n_r):
for j in range(n_c):
count[board[i][j]] += 1
if word[0] in count and word[-1] in count:
if count[word[0]] > count[word[-1]]: #reverse is more likely
word = word[::-1]
# pruning option 2
for c in word:
if count[c]:
count[c] -= 1
else:
return False
def dfs( idx, r, c):
if r<0 or r>=len(board) or c<0 or c>=len(board[0]):
return False
if board[r][c]!=word[idx] or board[r][c]==".":
return False
if idx == len(word)-1:
return True
prev=board[r][c]
board[r][c]="."
for dr,dc in neighbors:
nr,nc = r+dr, c+dc
if dfs( idx+1, nr, nc):
return True
board[r][c]=prev
return False
neighbors = ((1,0), (-1,0), (0,1), (0,-1))
for r in range(n_r):
for c in range(n_c):
if(word[0]==board[r][c]): #case 3
if dfs( 0, r,c):
return True
return FalseMake sure you share your thoughts on this question/solution/any interesting questions/developments in the comments or through my links.
Happy Prep. I’ll see you at your dream job.
Graphs are my best friends,
Devansh <3
Reach out to me on:
Instagram: https://www.instagram.com/iseethings404/
Message me on Twitter: https://twitter.com/Machine01776819
My LinkedIn: https://www.linkedin.com/in/devansh-devansh-516004168/
My content:
Read my articles: https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Get a free stock on Robinhood. No risk to you, so not using the link is losing free money: https://join.robinhood.com/fnud75