
Structurally-Aware Computation will take over AI and High Performance Computing
Understanding the US Government's Vision for the new paradigm of computing for high impact fields

It takes time to create work that’s clear, independent, and genuinely useful. If you’ve found value in this newsletter, consider becoming a paid subscriber. It helps me dive deeper into research, reach more people, stay free from ads/hidden agendas, and supports my crippling chocolate milk addiction. We run on a “pay what you can” model—so if you believe in the mission, there’s likely a plan that fits (over here).
Every subscription helps me stay independent, avoid clickbait, and focus on depth over noise, and I deeply appreciate everyone who chooses to support our cult.
PS – Supporting this work doesn’t have to come out of your pocket. If you read this as part of your professional development, you can use this email template to request reimbursement for your subscription.
Every month, the Chocolate Milk Cult reaches over a million Builders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission)- https://forms.gle/Pi1pGLuS1FmzXoLr6
A while back, I spoke to a few experts about why the US Government was looking at new computing paradigms for various challenges in AI, Nuclear Energy, and Personalized Medicine. The current computational paradigm struggles with a major challenge: the fundamental unit of computation, FLOPs (floating-point operations per second), is too crude for many high-impact fields, where the outcomes are not predictable or stable.
In more detail, these fields have two challenges that make them difficult to deal with. Firstly, the data associated in these domains is “truly sparse”. In contrast to AI Sparsity (“many zeros in a known dimension grid”), we encounter true structural complexity, primarily manifesting in three ways:
Pointer-chasing sparsity: You don’t know what data you need until runtime.
Multi-level indirection: Arrays of arrays of arrays, with conditionals between them.
Branch-heavy compute: Every thread might take a different path.
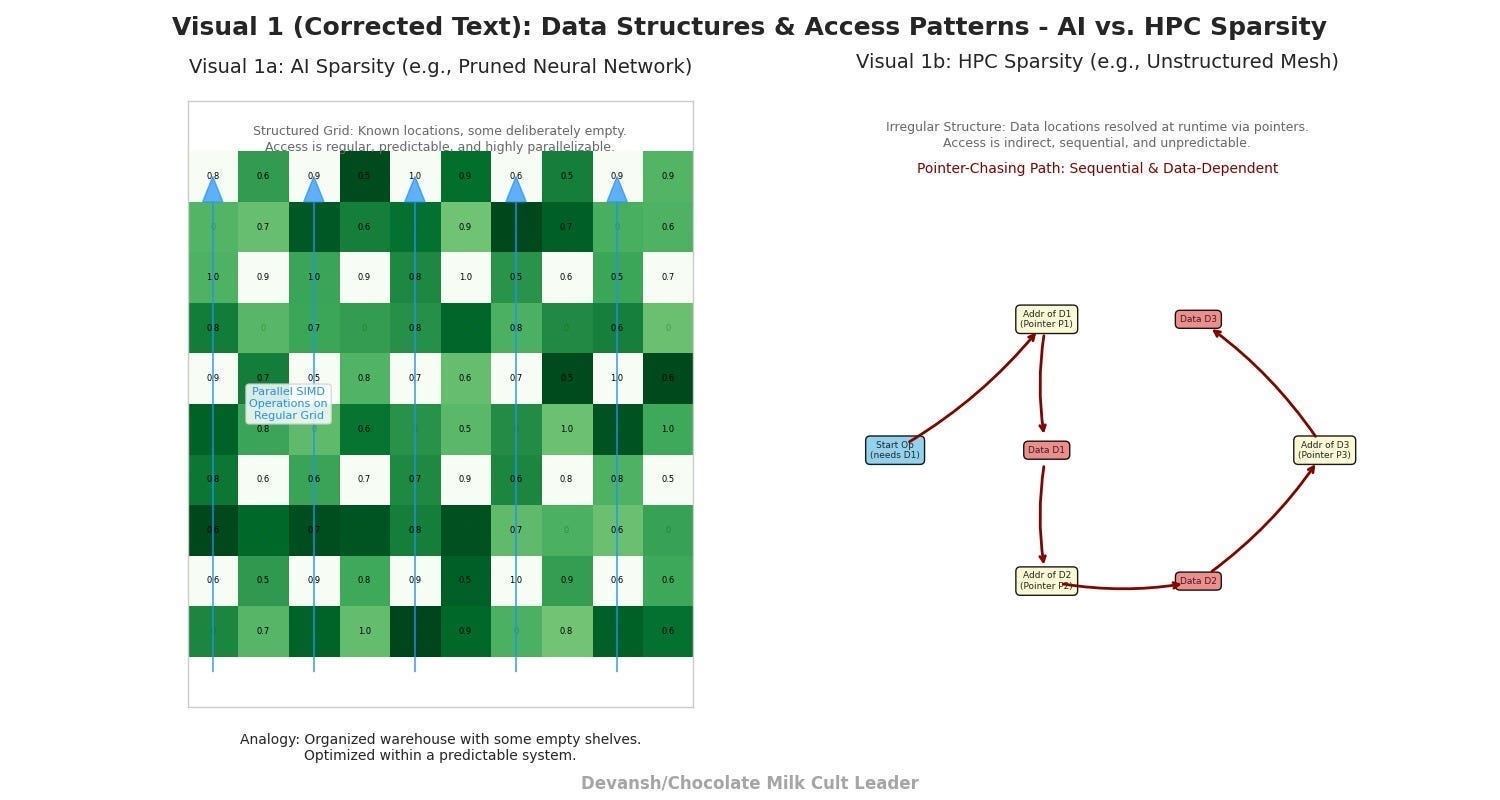
Second, we have conditional computing, where the result is decided in real time based on a multitude of conditions. On massively parallel architectures like GPUs, where thousands of cores try to execute the same instruction (SIMD/SIMT), branch divergence forces many cores to idle, shattering parallelism. This can account for ~25% of operations.
Structurally aware computing is the answer to both these questions. Today, I’m going to take a financial lens and try to understand how much this market is worth, what the timelines for ROI is, and where the first opportunities will manifest.
This fundamental architectural mismatch has created a massive, systemic mispricing of computational value. The appendix that follows is the economic doctrine for exploiting it.
Executive Highlights (TL;DR of the Article)
This fundamental architectural mismatch has created a massive, systemic mispricing of computational value. The appendix that follows is the economic doctrine for exploiting it.
The Arbitrage Opportunity (The “Sparsity Tax”): By solving the structural and conditional compute problems, specialized architectures can deliver a 5–10x+ improvement in performance-per-dollar and performance-per-watt. This isn’t an incremental gain; it’s a TCO-crushing advantage that makes the continued use of general-purpose hardware for these tasks economically indefensible.
The Hardware Solution (Concrete & Emerging Tech): The value will be captured by a new class of silicon, including:
Processing-in-Memory (PIM): Commercial solutions from companies like UPMEM are already demonstrating orders-of-magnitude speedups by computing where data resides.
Custom Accelerators: Agile, open-source RISC-V allows for specialized instructions and memory hierarchies co-designed to attack these specific bottlenecks.
Advanced Memory: Next-gen MRAM and other non-volatile memories offer new paradigms for low-power, data-intensive computation.
The Market Conquest (A Three-Phase Campaign):
Phase 1 (The Beachhead): First, capture the immediate ~1B− 4B addressable market in government and scientific HPC where the need is non-negotiable, de-risking the technology.
Phase 2 (Vertical Disruption): Next, enable entirely new multi-billion-dollar commercial verticals (e.g., computational drug discovery, generative materials) that are currently computationally impossible.
Phase 3 (Platform Dominance): Finally, address the universal “memory problem” to capture a significant share of the future multi-trillion-dollar global compute infrastructure market.
The Winning Play (Software is the Kingdom): The ultimate winner will not be a single chip design. Value will accrue disproportionately to the software ecosystem integrator — the entity that builds the compilers, libraries, and programming models that make this new hardware accessible and dominant.
Actionable Investment Theses: The core strategies involve investing in “structural silicon” pioneers, arming the “picks-and-shovels” of advanced packaging, backing domain-specific co-design for clear ROI, and owning the “software bridge” that connects legacy code to the new paradigm.
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
Strategic Financial & Investment Analysis — The Emerging Paradigm of Structurally-Aware Computation
(Detailed math available to founding subscribers on request. Once you get a founding subscription, email me devansh@svam.com. We also provide individual reports to our clients.) All references to the main article refer to our main report on this topic— The Great Compute Re-Architecture: Why Branching & Sparsity Will Define the Next Decade of Silicon— available for free over here.

Preamble
The following analysis moves beyond surface-level market sizing to explore the underlying economic drivers, value inflection points, strategic challenges, and potential asymmetric opportunities presented by the shift towards computational architectures optimized for structural complexity (i.e., extreme sparsity and branching). This is predicated on the understanding that current mainstream HPC and AI hardware trends are increasingly divergent from the needs of a critical set of scientific, national security, and nascent commercial workloads.
Foundational Assumptions & Market Context
Diminishing Returns of Brute-Force Scaling for Complex Problems: While overall compute demand grows, the marginal utility of adding more general-purpose FLOPS/memory bandwidth to structurally complex problems (characterized by high indirection, low arithmetic intensity, frequent branching) is decreasing. This creates an “inefficiency arbitrage” opportunity. For critical workloads at institutions like Los Alamos National Laboratory (LANL), the majority of operations (60%) involve memory and integer operations, specifically indirect load/store, due to unstructured meshes, sparse matrices, and adaptive mesh refinement. This indicates that raw FLOPS are not the primary bottleneck; instead, inefficient handling of irregular data access patterns is the limiting factor. Quantitative analysis shows that over 50% of all instructions in nuclear security applications are sparse memory operations resulting from indirection, and that routines are “mostly or completely main-memory bound” (0.001–0.2 FLOP/byte). This exceptionally low FLOP/byte ratio confirms that performance is overwhelmingly limited by data movement and access, validating the “inefficiency arbitrage” as a fundamental, data-backed market opportunity.
“Problem-Driven” vs. “Hardware-Driven” Innovation Cycles: The current dominant paradigm is largely hardware-driven (newer, bigger GPUs/CPUs enable new software). The shift targets a problem-driven cycle, where the unique demands of intractable problems dictate novel hardware/software co-design. For the United States to continue benefiting from advances in computing, “investments in deeper co-design of hardware and software — addressing levels of branching and sparsity not found in machine learning or most other major market applications — will be needed”. This highlights a “gap in technologies” for complex workloads with high sparsity and significant branching, which are poorly served by commodity CPUs and GPUs. Current work at LANL, focusing on “Codesign for memory-intensive applications” and addressing sparsity through software and hardware prototypes, exemplifies this problem-driven approach.
Long Gestation, High Impact: Fundamental architectural shifts are capital-intensive and require 5–10+ year horizons. However, successful shifts can redefine market leadership and create multi-decade technological moats. Complex simulations, such as a 3D simulation on the Sierra supercomputer, have required “nearly a year and a half” to complete, and achieving higher fidelity simulations took “more than a decade”. While core architectural shifts remain long-term endeavors, the emergence of “rapid co-design cycles” through the “commoditization of processor design and fabrication” (e.g., RISC-V Chipyard and FPGA prototyping) is increasing development agility and potentially offering earlier validation points.
Sovereign & Strategic Imperatives as Initial Catalysts: National security, fundamental science (e.g., fusion, climate), and critical infrastructure resilience will likely be the initial, non-negotiable drivers for investment, de-risking early-stage R&D before broader commercial viability is proven. LANL’s work is a prime example, with advances in computational capabilities deemed “absolutely essential” for the U.S. nuclear deterrent, and sparsity and branching highlighted as “root challenges” for nuclear security applications. This strategic demand provides a de-risked “seed” market with guaranteed funding, independent of immediate commercial viability.
Data Movement as the True Bottleneck: Increasingly, the cost (time, energy) of moving data far exceeds the cost of computation itself for these workloads. Solutions that minimize or intelligently manage data movement will hold a premium. As noted, 60% of operations in relevant workloads are memory and integer operations, and over 50% are sparse memory operations, with routines being “mostly or completely main-memory bound”. Beyond these specific workloads, the memory system is responsible for “most of the energy consumption, performance bottlenecks, robustness problems, monetary cost, and hardware real estate of a modern computing system”. Main memory alone can be responsible for over 90% of system energy in commercial edge neural network models, and over 62% of total system energy is wasted on moving data in mobile workloads. This elevates the “data movement bottleneck” from a specific problem for sparse/branching workloads to a fundamental, escalating issue across all data-intensive applications, including mainstream AI, implying broader market applicability for solutions.
Value Unlocking Stages & Market Sizing
Phase 1: Specialized Acceleration & Efficiency Gains (Next 2–5 Years)
Value Driver: Significant TCO reduction (power, footprint, time-to-solution) for existing, well-defined, structurally complex workloads in government labs, research institutions, and highly specialized industries (e.g., advanced materials, niche drug discovery, high-frequency trading with complex order books).
Market Estimate:
Current Global HPC Market: The total HPC market, which provides context for this phase, was estimated at USD 57.00 billion in 2024 and is projected to reach USD 87.31 billion by 2030.

Initial Addressable Market (IAM): Annual global spend on HPC systems for these specific problem classes, closely aligned with the “AI Enhanced HPC Market,” was valued at USD 3.12 billion in 2024. This market is projected to grow to USD 7.5 billion by 2034
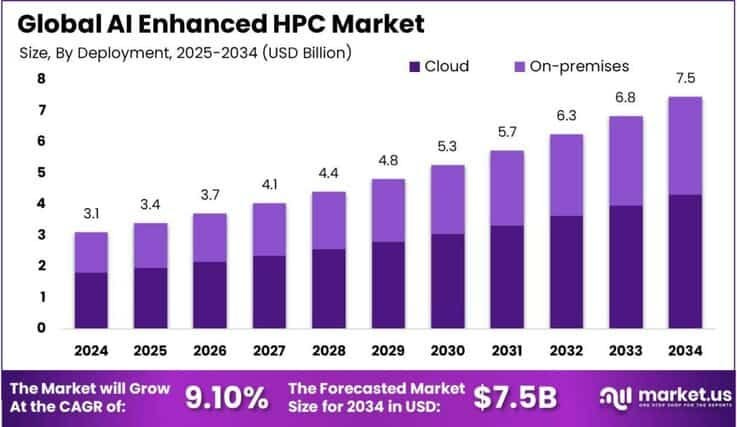
Potential Value Capture: Accelerators/co-processors offering 5–10x performance/dollar for these niches could capture 20–30% of this IAM. Applying this to the updated 2024 IAM of $3.12 billion, this leads to a $624M–$936M annual market for specialized hardware solutions. Empirical evidence from LANL demonstrates substantial performance improvements (e.g., 89% and 185% throughput increase) with specialized memory access accelerators.
Software and Integration Services: Could add another $200M–$500M. The strategic importance of software and the ecosystem is increasingly recognized, with value potentially accruing disproportionately to the software ecosystem integrator in the long term.
Key Players: Boutique hardware startups, semiconductor majors exploring custom silicon (ASICs/FPGAs via programs like Intel IFS or TSMC shuttle runs), academic spin-outs.
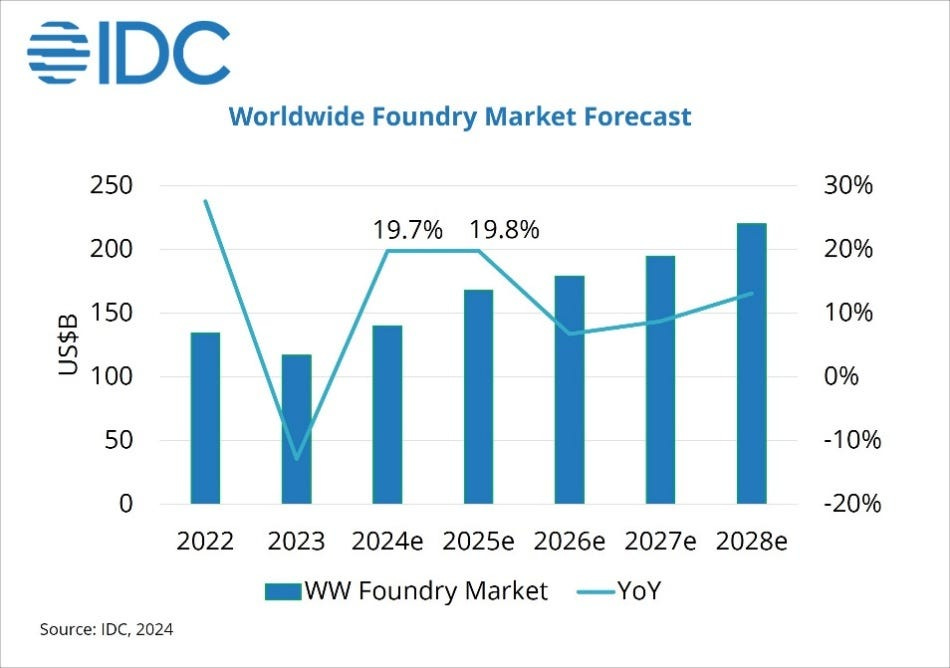
Many VCs will deem this initial market “too small.” However, this perception is rapidly shifting. The datacenter processor market, valued at $136.3 billion in 2024, shows ASICs as a fast-growing segment.
Hyperscalers are actively driving the growth of custom silicon, and there is significant merger and acquisition activity as established players seek to incorporate cutting-edge technologies in the HPC and AI accelerator market. The strategic play is for acquirers (large semiconductor firms, defense contractors, cloud providers with HPC offerings) seeking unique IP and early access to a paradigm shift.
Phase 2: Enabling New Capabilities & Vertical Market Disruption (Next 5–10 Years)
Value Driver: The ability to solve problems previously considered computationally intractable, leading to new product/service categories.
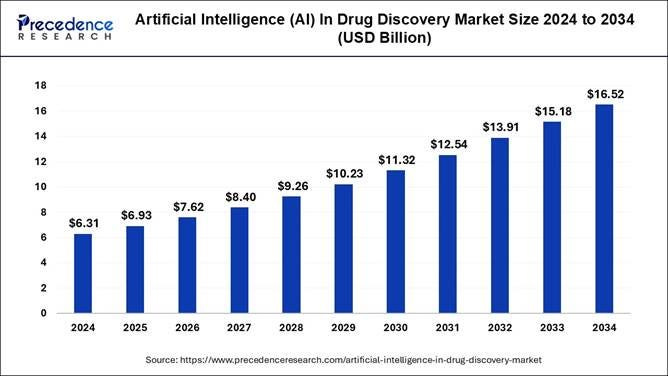
Example 1: Computational Drug Discovery Moving beyond QSAR/docking to full biophysical system simulation for predicting efficacy and toxicity, drastically reducing wet-lab costs. The global computer-aided drug discovery (CADD) market was $2.9 billion in 2021 and is projected to reach $7.5 billion by 2030. More specifically, the “AI in Drug Discovery Market” was already $6.31 billion in 2024 and is expected to reach $16.52 billion by 2034. The broader biosimulation market is forecast to reach $9.65 billion by 2029.
Example 2: Generative Engineering & Materials Science. Inverse design of materials/structures with specific properties based on first-principles simulation. The “Generative Artificial Intelligence (AI) in Material Science Market” was valued between $1.1 billion and $1.26 billion in 2024. This market is projected to reach $5.35 billion by 2029 or $11.7 billion by 2034.
Example 3: Hyper-Realistic Digital Twins for Critical Infrastructure Predictive maintenance, operational optimization, and resilience planning for energy grids, supply chains, urban systems. These applications inherently involve sparse, dynamic, and branching data structures, representing a significant latent opportunity for structurally-aware computation to enable higher fidelity and predictive power.
Market Estimate: This is harder to quantify as it’s new market creation. Each successful vertical could represent a $5B–$50B+ total addressable market (TAM) for the enabling computational platforms and associated software/services. Based on current market trajectories for computational drug discovery and generative materials science, these figures appear realistic, and potentially conservative on the lower end. Success in 3–5 such verticals implies a cumulative TAM of $15B–$250B.
Key Players: Consortia of domain experts, software companies building vertical-specific platforms, and the hardware providers from Phase 1 who achieve sufficient scale and programmability.
The “killer app” may not emerge from the initially targeted government/science domains but from an unexpected commercial application where structural complexity is a hidden but critical bottleneck (e.g., advanced financial modeling, logistical optimization at extreme scale, certain classes of AI inference for robotics/autonomous systems with highly dynamic environments). The rise of SLMs (Small Language Models), designed to reduce memory usage, computational operations, and energy consumption for AI models, particularly for edge devices, directly aligns with this potential.
One thing that both the release of ChatGPT and Open Source Gen AI have taught us is that making powerful technology more accessible allows completely new entrants to see things that traditional experts miss. Smart investors, founders, and decision makers should be proactive in identifying these blind spots and emergent solutions before anyone else.
Phase 3: Paradigm Shift & Horizontal Platform Dominance (10+ Years)
Value Driver: The underlying architectural principles and software ecosystems developed for structural computation become so effective and generalizable (for non-uniform workloads) that they begin to displace or significantly augment existing general-purpose compute paradigms in HPC, specialized AI, and large-scale data analytics. This is driven by the pervasive “memory problem” in computing, where the memory system is responsible for most of the energy consumption, performance bottlenecks, and monetary cost in modern systems. The widening “memory wall,” where processing performance has skyrocketed by 60,000x over two decades while DRAM bandwidth has only improved 100x, underscores the need for this fundamental shift.
Market Estimate: This is about capturing a share of the future multi-trillion-dollar global compute infrastructure market. “The global data center processor market neared $150 billion in 2024 and is projected to expand dramatically to >$370 billion by 2030, with continued growth expected to push the market well beyond $500 billion by 2035.” If these architectures can address even 10–20% of workloads poorly served by current von Neumann/GPU-centric designs, this represents a $200B–$1T+ annual revenue potential for hardware, software, and cloud services.
Key Players: The winners from Phase 2 who successfully built out a robust, programmable, and developer-friendly ecosystem. Potential for new semiconductor giants to emerge or for existing ones to pivot successfully. Innovative startups are already pioneering novel architectures, including dataflow-controlled processors, wafer-scale packaging, spatial AI accelerators, and processing-in-memory technologies.
Commercially available Processing-in-Memory (PIM) hardware, such as UPMEM’s PIM modules, is now integrating general-purpose processors directly onto DRAM chips, demonstrating the active development of memory-centric architectures. The ultimate “winner” might not be a single hardware architecture but a highly adaptable software/compiler stack that can efficiently map structurally complex problems onto heterogeneous systems incorporating both general-purpose cores and specialized structural accelerators. The value accrues disproportionately to the software ecosystem integrator.
Personal Bias — Quantum computing, if it matures for certain problem classes, could complement rather than replace these structurally-aware classical systems, handling exhaustivesub-problems. Treat this more as my speculation/intuition, as opposed to strongly backed research
Key Investment Theses & Strategic Angles
The “Sparsity Tax” Arbitrage: Invest in technologies that explicitly reduce the “sparsity tax” — the performance penalty incurred by general-purpose hardware when dealing with irregular data. This includes novel memory controllers, in-memory compute, dataflow architectures, and compilers that can aggressively optimize for locality in sparse codes. Observed throughput improvements of 89% and 185% with specialized memory access accelerators demonstrate the potential for this arbitrage.

Ecosystem Enablers: Beyond silicon, the value lies in software. Compilers, debuggers, performance analysis tools, high-level programming models (DSLs tailored for sparsity/branching), and standardized sparse data formats will be crucial. Investments here can have outsized leverage. LANL’s active “Application and frameworks codesign” efforts (e.g., FleCSI, Kokkos, LLVM, MLIR) reinforce the importance of this layer. RISC-V plays a role here by fostering open ISA experimentation.
Domain-Specific Co-Design Verticals: Instead of generic “sparse accelerators,” focus on companies co-designing solutions for specific high-value verticals (e.g., computational biology, materials informatics) where the problem structure is well-understood, and a clear ROI can be demonstrated. The rapid growth of the “AI in Drug Discovery Market” and “Generative AI in Material Science Market” validates this approach.
“Picks and Shovels” for Advanced Packaging: Solutions that tackle structural complexity will likely involve heterogeneous integration (chiplets). Companies providing critical IP, tools, or services for advanced 2.5D/3D packaging will benefit indirectly but significantly. GPUs are heavily relying on advanced packaging technologies like CoWoS, Foveros, and EMIB to exceed 2.5KW, and demand for high-end logic process chips and high-bandwidth memory (HBM3, HBM3e, HBM4) is increasing due to AI accelerators.
The “Memory-Centric Computing” Long Bet: The most radical (and potentially highest reward) thesis is that the von Neumann bottleneck is insurmountable for these problems, and a fundamental shift to architectures where computation happens much closer to, or within, memory is inevitable. This encompasses processing-in-memory (PIM), computational memory, and non-volatile memory technologies with compute capabilities.
Real PIM hardware has recently become commercially accessible, with companies like UPMEM offering PIM modules that integrate general-purpose processors directly onto DRAM chips. “According to a report by Polaris Market Research, the total addressable market (TAM) for MRAM is projected to grow to USD $25.1 billion by 2030, at a CAGR of 38.3%. Numem is poised to play a pivotal role in this growing market, sitting at the intersection of AI acceleration and memory modernization.”
Asymmetric Opportunities
Shorting the “AI Hardware Bubble” (Selectively): While AI is transformative, the current valuation of some general-purpose AI hardware companies might not fully price in their limitations for other complex, non-AI workloads that will become increasingly important. Hyperscalers committed $200 billion in twelve-month trailing capital expenditures in 2024, with projections reaching $300 billion in 2025, raising questions about efficiency for all workloads. A nuanced strategy might involve identifying companies over-indexed on purely dense AI paradigms with limited adaptability (High risk, requires precise timing).
The “Software Bridge” Play: Invest in companies developing highly sophisticated compiler technology that can efficiently map existing sparse codes (Fortran, C++, MPI) onto emerging novel architectures. This reduces the adoption friction for new hardware and captures value as an intermediary.
Non-Semiconductor Material Innovations for Memory: Breakthroughs in memory materials (e.g., phase-change memory, MRAM, resistive RAM) that offer new trade-offs in density, latency, endurance, and potential for in-situ computation could disrupt the current DRAM/SRAM dominance and create openings for new architectures. Companies like Numem are developing foundry-ready, MRAM-based AI Memory Engines that address memory bottlenecks with significantly lower power consumption than traditional SRAM and DRAM.
Open Source Hardware Verification & EDA Tools: As more custom silicon (especially RISC-V based) is developed for these niches, there’s a growing need for robust, cost-effective open-source or source-available verification and Electronic Design Automation (EDA) tools. This is a critical infrastructure gap.
Talent Incubation & Specialized Education: The bottleneck for this entire field will eventually be human capital. Strategic investments in programs that cross-train computer architects, software engineers, and domain scientists for co-design will yield long-term dividends for nations or corporations that pursue this.
Geopolitical & Sovereign Implications Technological Sovereignty:
Nations that develop domestic capabilities in designing and fabricating these specialized computational systems will gain a strategic advantage, reducing reliance on potentially adversarial or supply-chain-constrained foreign entities, especially for defense and critical infrastructure. Global initiatives like the CHIPS Act and the push for localized, secure supply chains underscore this imperative.
“Computational Decoupling”: If mainstream hardware (largely optimized for consumer/enterprise AI) continues to diverge from strategic national needs, leading nations may accelerate investment in bespoke “sovereign compute” initiatives, creating a parallel, non-commercial innovation track. LANL’s focus on specialized hardware-software co-design for unique, high-priority workloads is a prime example of this divergence.
Export Controls & IP Protection: As these technologies demonstrate strategic value, they will inevitably become subject to intense scrutiny regarding intellectual property rights and export controls, similar to current advanced semiconductor and AI restrictions. Ongoing trade tensions and evidence of GPU transshipment highlight the real-world impact of these policies.
Conclusion for Appendix
The transition to structurally-aware computation is not a minor architectural tweak; it represents a potential paradigm shift with profound economic, strategic, and geopolitical consequences. While the path is long and fraught with technical and market challenges, the rewards for those who successfully navigate it — whether as innovators, investors, or national strategists — are commensurate with the difficulty of the problems being solved. The era of “one-size-fits-all” high-performance computing may be drawing to a close, ceding to a more specialized, problem-driven future.
Thank you for being here and I hope you have a wonderful day,
Dev <3
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).

If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819