
The Ethics of GitHub Copilot [Storytime Saturdays]
Are Code Generating Models like Copilot and ChatGPT ethical or useful? Viewed from the lens of a software developer.

To learn more about the newsletter, check our detailed About Page + FAQs
To help me understand you better, please fill out this anonymous, 2-min survey. If you liked this post, make sure you hit the heart icon in this email.
Recommend this publication to Substack over here
Take the next step by subscribing here
Following is a piece I was asked to write about the Ethics of Github Copilot. This was written in an academic context, so the structure/tone of this write-up will be different from my usual. However, this piece received a lot of positive feedback so I’m sharing it here. Given that this topic is very important for anyone in tech, and how much misinformation there is surrounding this, I will not be putting a paywall on this post. Consider it my Christmas Gift to you <3. If you’d like to support more such high-quality writing, consider getting a premium subscription.
You can also gift this newsletter to someone who would benefit from this. Use the button below to help someone level up their skills and make insane career gainzz.
With that out of the way, here is the write-up.
We’re living in the golden age of AI and Technology. Technology has shown staggering potential to reshape society. Thanks to an amazing track record and a lot of investment money, Tech has emerged as the dominant force in today’s world. The IT industry alone was valued at 9,358.51 billion in 2022 at a compound annual growth rate (CAGR) of 11.6% [1]. Thus, it is important to pay attention to the important developments surrounding the field, since they have the potential to shape society. Having informed conversations and intense discussions about the ethics of upcoming developments are crucial to minimizing the negative externalities of such a project.
One of the most potentially influential projects to come out in recent years is the GitHub Copilot. “GitHub Copilot uses the OpenAI Codex to suggest code and entire functions in real-time, right from your editor.” Developers can generate entire chunks of code given the function description and declaration. This goes beyond just simplistic implementations (which more advanced IDEs can do), as can be seen in the image below.
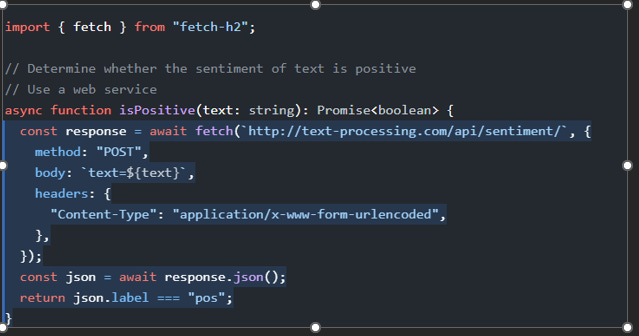
Given that it can generate code based on text prompts in English, many people have been presenting GitHub Copilot as the potential end to software engineers. Why pay for coders when you can use AI to generate the code for you? While that is the most obvious (and poetic) use-case, this technology has far-reaching implications in various ways that must be considered before this solution is brought up for mass adoption. Rushing to adopt this system too quickly would be foolish and a violation of ACM 3.7, ‘Recognize and take special care of systems that become integrated into the infrastructure of society’ [12] and would lead to terrible outcomes. It is important to evaluate Copilot comprehensively, understanding its strengths and its flaws.
We can understand these issues by evaluating the impact of Copilot on the various stakeholders. By doing so we can paint a more accurate picture of whether this technology is ethical. GitHub Copilot has great potential. However, in evaluating the impacts of GitHub copilot, we can see that it has several ethical flaws, violating ACM 1.2 (do no harm), ACM 1.6 (respect privacy) and other centrals tenets of the ACM code of ethics. These violations must be addressed to make it a truly viable solution.
The first major stakeholder impacted by Copilot, and the most overlooked, is the environment. In the typical anthropocentric way, people have been talking about legal and ethical edge cases and missed the giant elephant (killer) in the room- these models are extremely expensive to run. According to researchers who wrote, Estimating the Carbon Footprint of BLOOM, a 176B Parameter Language Model[3], it took roughly 50.5 tons of CO2 equivalent to train the large-language model BLOOM. GPT-3 released over 500 tons of CO2 equivalent. It is worth noting that Codex (the basis of Copilot [2]) is based on GPT-3 [4]. Please refer to the Table Below for more information

This is a very direct contradiction to the Code 1.2 of ACM, ‘Avoid Harm’. Here harm is defined as “negative consequences, especially when those consequences are significant and unjust”[12]. These extreme emissions are poised to cause severe damage to the environment, especially given that the world is currently dealing with climate change and mass extinction. Putting more strain on the environment is not justifiable.
However, there are a few reasons that the numbers of the paper don’t tell the full story in the context of Copilot. Firstly, Copilot is a very inference-heavy model. AWS estimates that “In deep learning applications, inference accounts for up to 90% of total operational costs” [6]. This means that Copilot (which has already got high costs/prediction) will put extreme demands on systems that run it.
While this is true for all Large Models, this is especially true for Copilot. This issue gets much worse when we think about Copilot being used to solve more complex/ambiguous problems. The authors of Codex acknowledged this. In their paper they wrote, “Looking more globally and long-term, the compute demands of code generation could grow to be much larger than Codex’s training if significant inference is used to tackle challenging problem” [5]. This means that Copilot is expensive on two accounts-
If it is used to automate simple tasks that can easily be written, it will be expensive to run at scale.
If it is used to automate more complex tasks, then the model will have very high individual inference costs. Given the scale at which software is written, it’s not hard to see a few runs putting a major strain on the energy requirements.
These costs will directly affect not just the environment, but also entire human societies. It has been well known that climate change will disproportionately affect poorer countries [13]. According to the WHO, “human-induced changes in the Earth’s climate now lead to at least 5 million cases of illness and more than 150,000 deaths every year “ [13]. The poorer countries will be the ones most vulnerable to climate and disease. This is a clear violation of the ACM code 3.1 since it does not promote public good [12]. ACM 1.1 holds all people as stakeholders in computing [12]. In contributing to environmental degradation, Copilot harms its own stakeholders.
There is also something about the nature of Codex and Copilot that make it questionable as long-term programing aids. And that boils down to the sheer amount of Data Drift in the Data used to train these models. Data Drift occurs when the data coming into the pipeline is significantly different from the data that was used to train the model [7]. In our case, this drift occurs because programming languages change very quickly. New variants of languages are always being added, frameworks/libraries change a lot, and sometimes new SOPs pop up. “As with other large language models trained on a next-token prediction objective, Codex will generate code that is as similar as possible to its training distribution. One consequence of this is that such models may do things that are unhelpful for the user” [5]
This puts Copilot at odds with ACM 2.1, which requires high quality in both processes and products [12]. The solutions built by Copilot will not be inline with the newest practices, tools, and principles.
To be useful as advertised, Copilot would need to change somewhat as fast as programming languages themselves change. This would require constant retraining and tuning. While techniques like Transfer Learning and Active Learning can reduce these frameworks, it will still be very expensive. These make Copilot unethical from an environmental perspective. In a world already grappling with climate change, Copilot doesn’t make sense. While Codex was trained using Green Energy + Carbon Credits (for a significant amount), the priorities are misplaced. As companies, OpenAI and Microsoft can do as they please, but in its present state, Copilot is not environmentally sustainable.
Moving on to humans affected by Copilot let’s first cover developers whose code makes up the dataset used to train Copilot. A common complaint is that Copilot generates code without any attribution. The common adage is that Large Language Models learn their datasets. By not attributing the samples they used to generate their output, Copilot would be plagiarizing they original coders. This violates ACM 2.3 (respect rules) and ACM 1.5 (which requires that creators be credited).
The claim that Copilot directly uses code from training samples is inaccurate. In reality, Copilot builds an embedding of their training data, and learns that. It’s not dissimilar to how we learn by spotting patterns. The code it generates is often the result of thousands of input samples (even some that may seem unrelated). In such a case, should Copilot be expected to cite the inspirations? No person would have to, therefore drawing the line at Copilot seems a little arbitrary. To show that a particular developer/group of developers are not being attributed for their work, we would need to show that their inputs majorly influenced the output, which would be very unlikely (and hard to prove).
However, there is a concern that needs to be addressed going forward. Certain Developers upload their code to Github and don’t want Copilot using it. [9] contains one such example, where the user noticed that GitHub Copilot was sharing his copyrighted code (even though it wasn’t public). He was able to show that Copilot was producing his code exactly, with only the license stripped off. This needs to be fixed. Developers should be given the choice whether their samples are used, especially with copyright.
This example is extremely concerning because it shows a violation of some very important principles. Obviously, this violates ACM 1.7, since it violates the confidentiality of the software that the developer created. However, the [9] also shows that Copilot is not respecting privacy which is enshrined in ACM 1.6. The original developer uses his name in the prompt to generate code in his style [9]. Copilot does so. This means that Copilot is also trained on the user data, beyond just the code. This is clearly not “the minimum amount of personal information” [12] mandated by ACM 1.6.
This lack of differentiation is something that Copilot needs to resolve to not violate copyright violate people’s trust. As the Columbia Law Professor Eben Moglen pointed out, “Ideally, users should have the ability to filter recommendations automatically to avoid the unintentional incorporation of code with conflicting or undesired license terms."[8] This would be necessary to ensure that both users and the developers whose code trained the datasets are not hurt inadvertently.
Now for the final major stakeholders that would be influenced by Copilot. Software Devs. Have we created a Frankenstein’s Monster, that will replace us all? Can we kick up our boots and let Copilot handle all our work (assuming we ignore the energy costs)? Unfortunately, not. Copilot is terrible. Fast AI has an exceptional writeup investigating Copilot [10]. One of their stand-out insights was- “According to OpenAI’s paper, Codex only gives the correct answer 29% of the time. And, as we’ve seen, the code it writes is generally poorly refactored and fails to take full advantage of existing solutions (even when they’re in Python’s standard library).” They provide several examples of this.
Copilot will not cause mass developer layoffs. It will help developers massively by helping them write routine functions, but it will not hurt developer jobs as much as advertised. In this context, it is fully compliant with ACM since it will boost developer productivity. Furthermore, Copilot encodes the coding behavior in millions of lines of code. This can be great to study these behaviors and glean valuable insights. This is in-line with ACM 3.5, since it frees up time and thus creates “opportunities for members of the organization or group to grow as professionals” [12].
There is one final problem, associated with Copilot that needs to be addressed. This is true off all LLMs but might be particularly problematic if Copilot Code is deployed into systems. This is the problem of adversarial suggestion. LLMs tend to treat their inputs as ground truth. This is true regardless of how cutting-edge the model gets. Researchers working on Google’s Groundbreaking Flamingo Model showed that you could fool the models, prompting ‘hallucinations’ and incorrect output [11] (image below). [10] shows a similar idea when they ask Copilot to create a regular expression that can parse Python (an impossible task). If developers are not critical of examining the code, they can create potentially harmful products. Systems built on Copilot would not be ‘robustly and usably secure’ [12] as mandated by ACM 2.9.

Therefore, we can see that Copilot is a very nuanced topic. On a technical level, it can help us study the coding habits of millions of people. This can lead to lots of insights and truly help us study software at a field. However, in its current state, it comes with 3 major problems- a huge hit to the environment, tendency to ignore licenses from developers, and a potential to mislead developers. While it is not the Big Tech Overlord Supremacy tool that some people have made it out to be, it needs changes to be a more ethical tool.
Sources-
Sources last accessed on 12/4/22.
1. “Information Technology Market Size 2022 and Growth Analysis.” Www.thebusinessresearchcompany.com, www.thebusinessresearchcompany.com/report/information-technology-global-market-report#:~:text=The%20global%20information%20technology%20market.
2. “GitHub Copilot · Your AI Pair Programmer.” GitHub, github.com/features/copilot.
3. arXiv:2211.02001 [cs.LG]
4. “OpenAI Codex.” OpenAI, 10 Aug. 2021, openai.com/blog/openai-codex/.
5. arXiv:2107.03374 [cs.LG]
6. “Amazon Elastic Inference - Amazon Web Services.” Amazon Web Services, Inc., aws.amazon.com/machine-learning/elastic-inference/. Accessed 4 Dec. 2022.
7. “This Can Destroy Machine Learning Models. Data Drift Introduced. Machine Learning Terms.” Www.youtube.com, youtu.be/qBmAwvGKvas. Accessed 4 Dec. 2022.
8. “Sure, GitHub’s AI-Assisted Copilot Writes Code for You, but Is It Legal or Ethical?” ZDNET, www.zdnet.com/article/is-github-copilots-code-legal-ethically-right/.
9.

10. Howard, Jeremy. “Fast.ai - Is GitHub Copilot a Blessing, or a Curse?” Www.fast.ai, 19 July 2021, www.fast.ai/posts/2021-07-19-copilot.html.
11. Simple, Devansh-Machine Learning Made. “3 Overlooked Things Deepmind Flamingo: A Large Model for Computer Vision.” Geek Culture, 28 May 2022, medium.com/geekculture/3-overlooked-things-deepminds-flamingo-a-large-model-for-computer-vision-84cd9d2f738c. Accessed 4 Dec. 2022.
12. Association for Computing Machinery. “ACM Code of Ethics and Professional Conduct.” Acm.org, Association for Computing Machinery, 22 June 2018, www.acm.org/code-of-ethics.
13. “Third World Bears Brunt of Global Warming Impacts.” News.wisc.edu, news.wisc.edu/third-world-bears-brunt-of-global-warming-impacts/.
Loved the post? Hate it? Want to talk to me about your crypto portfolio? Get my predictions on the UCL or MMA PPVs? Want an in-depth analysis of the best chocolate milk brands? Reach out to me by replying to this email, in the comments, or using the links below.
Stay Woke,
Go kill all,
Devansh <3
Reach out to me on:
Instagram: https://www.instagram.com/iseethings404/
Message me on Twitter: https://twitter.com/Machine01776819
My LinkedIn: https://www.linkedin.com/in/devansh-devansh-516004168/
My content:
Read my articles: https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Get a free stock on Robinhood. No risk to you, so not using the link is losing free money: https://join.robinhood.com/fnud75