
Understanding Hashing [Math Mondays]
The concept behind hashing comes up in a couple of places

Happy Monday my lovely reader,
I have something real special for you today. We are going to cover hashing. This is a very important idea that shows up in a lot of places. You know the most common application, in the amazing Dictionaries or Sets. Both these data structures use Hashing to ensure the constant time lookups and insertions. However, this idea shows up in more places from databases to some very trick coding interview problems. Thus it is important to understand the basics of hashing.
Highlights
In this post, we will cover the following ideas-
What is hashing and why it leads to efficient results- Hashing is a way to map the contents of a larger data structure to an integer. Using this int, we search for the data structure quickly.
Things you want to look out for/Design choices- How you handle collisions (2 inputs mapping to the same hash value), some nuances in different use case
Rolling hash- How the technique works, where you can use it. Really basic stuff.
If these ideas sound interesting to you, let’s jump in.

Hashing: The Idea
Hashing is simply the process of taking a long data structure and running it through some function (called a Hash Function). This function will return an integer, representing the hash value.
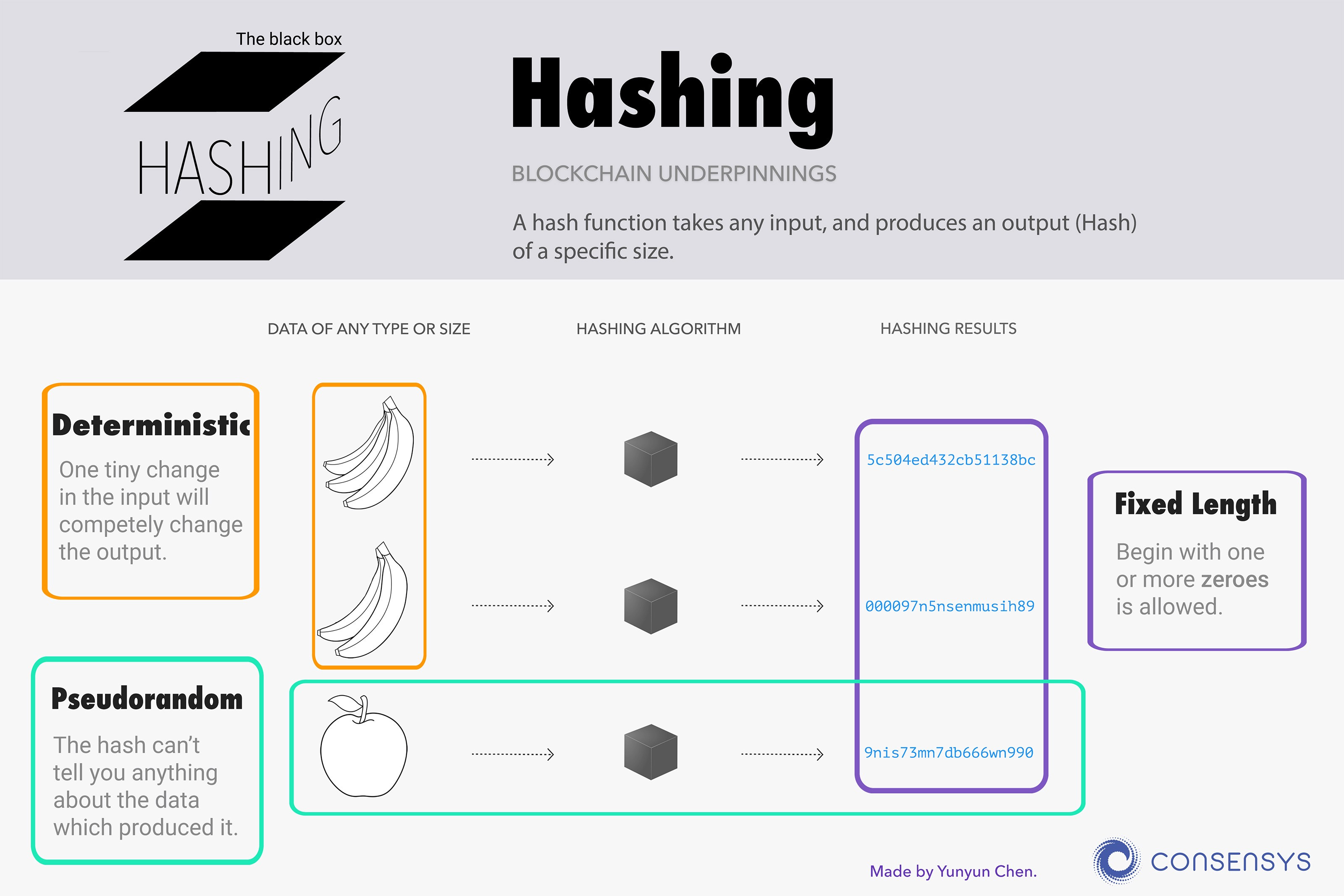
Let’s take a simple example. Imagine I wanted to hash a string. A simple hash function could be summing over the string, letter by letter. For each char, we take its place in the alphabet and add that to our sum. So our string “aba” would result in 1+2+1= 4.
…So why are we doing this?
Now imagine we wanted to search through a large set of words, to see if aba was a part of it. Searching through it linearly would be super slow. Even if our set was ordered, binary search is still only logarithmic at best.
But if we have our values hashed with our function, all we need to do is search for the associated hash value. This is much quicker, and we can quickly check if we added the string to our set.
To understand this more, let’s go into the next step.
How Hashing is implemented
So how are HashMaps implemented? It’s much easier than you would think. We need a few things-
A hash function like we discussed earlier.
An array that will act as our hash map.
When we want to add input, all we need to do is run through the hash function. The hash value we get is the index on our array. So we boop over to the array index, and we put the input into that index. Naturally, in search problems, we would check if the value exists at the given index. If we wanted to delete a value from our index, we just need to remove the input from the index.

Such a system makes it very quick to insert, lookup, and delete a large number of values from your dataset (assuming that your hash function is efficient). However, there are some considerations we have to make.
Design Choices
Hash Functions make or break you. However, we won’t cover them too much since the math can get out of hand. You will most likely either create very simple hash functions or the inbuilt ones.
One of the biggest concerns when using hashing is how we resolve collisions. Collisions occur when two input values result in the same hash code. There are two ways of handling it-
Separate Chaining- At each index of our hash array, we have a LinkedList. When an input hits an index, we simply append it to the LinkedList. So given input, we just need to go to the location given by our hash function and do our thing.
Open Probing- If a collision occurs then we look for availability in the next spot generated by an algorithm. This can be slower than chaining. Open Addressing is generally used where storage space is restricted, i.e. embedded processors.
As we have more values added, we say that the load of our hash table increases. Typically, when this happens, we increase the size of our hashing array and transfer the values into their new locations.
Rolling Hash Explained.
A rolling hash is used when we are searching for substrings within a much bigger string. This is a fairly common problem in both interviews and IRL.
We could just go interval by interval recomputing the hash of our strings from scratch. However, this is extremely slow and inefficient. Also, remember using String Comparison operators will slow you down because they compare strings char by char. For long substrings, in even longer strings, this complexity would get out of hand.
To explain this idea, suppose we wanted to match the pattern "cat" against the string "scatter". We are using our extremely simple hash function, where we assign each letter in the alphabet a value: a = 1, b = 2, ..., z = 26 and then add up the values of each letter in the hash. For example, simple_hash("cat") would be 3 + 1 + 20 = 24.
To find our pattern matches, we start by comparing "cat" to "sca". Since simple_hash("sca") = 19 + 3 + 1 = 23, we know we have not found a match, and we can continue. This is where the rolling part comes in. Instead of computing the hash value for the next window from scratch, there is a constant-time operation we can do: subtract the value of "s" and add the value of "t". And in fact, we find that 23 - value(s) + value(t) = 24, so we have a match!
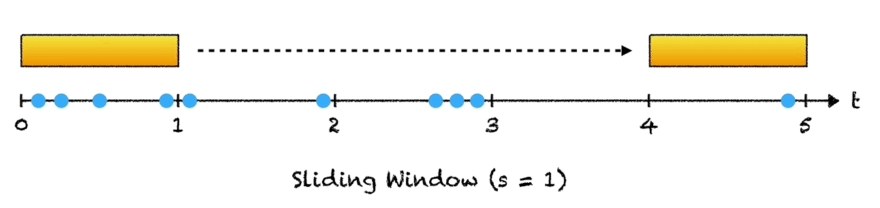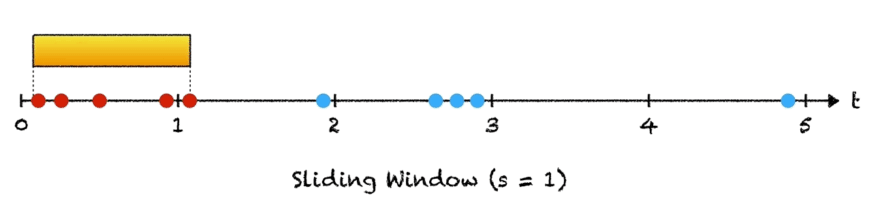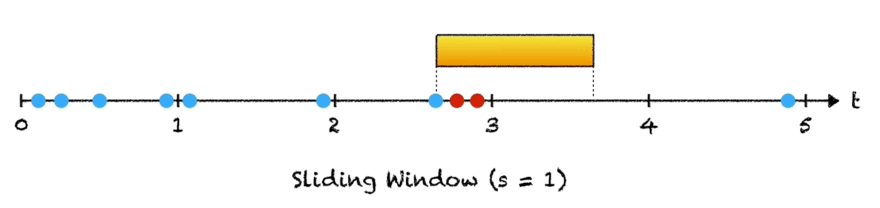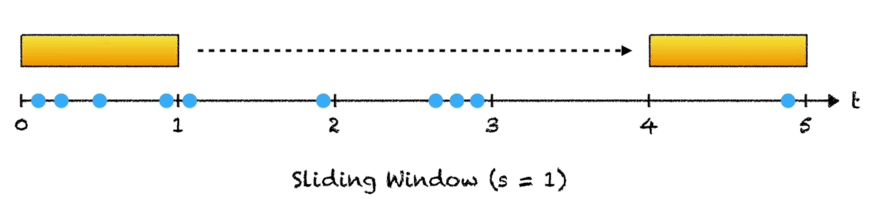
Continuing in this way, we slide along the string, computing the hash of each slice and comparing it to the pattern hash. If the two values are equal, we check character by character to ensure that there is indeed a match and add the appropriate index to our result.
Before proceeding, if you have enjoyed this post so far, please make sure you like it (the little heart button in the email/post). I also have a special request for you.
***Special Request***
This newsletter has received a lot of love. If you haven’t already, I would really appreciate it if you could take 5 seconds to let Substack know that they should feature this publication on their pages. This will allow more people to see the newsletter.
There is a simple form in Substack that you can fill up for it. Here it is. Thank you.
https://docs.google.com/forms/d/e/1FAIpQLScs-yyToUvWUXIUuIfxz17dmZfzpNp5g7Gw7JUgzbFEhSxsvw/viewform
To get your Substack URL, follow the following steps-
Open - https://substack.com/
If you haven’t already, log in with your email.
In the top right corner, you will see your icon. Click on it. You will see the drop-down. Click on your name/profile. That will show you the link.

You will be redirected to your URL. Please put that in to the survey. Appreciate your help.
In the comments below, share what topic you want to focus on. I’d be interested in learning and will cover them. To learn more about the newsletter, check our detailed About Page + FAQs
If you liked this post, make sure you fill out this survey. It’s anonymous and will take 2 minutes of your time. It will help me understand you better, allowing for better content.
https://forms.gle/XfTXSjnC8W2wR9qT9
Happy Prep. I’ll see you at your dream job.
Go kill all you beautiful beast,
Devansh <3
To make sure you get the most out of Math Mondays, make sure you’re checking in the rest of the days as well. Leverage all the techniques I have discovered through my successful tutoring to easily succeed in your interviews and save your time and energy by joining the premium subscribers down below. Get a discount (for a whole year) using the button below
Reach out to me on:
Instagram: https://www.instagram.com/iseethings404/
Message me on Twitter: https://twitter.com/Machine01776819
My LinkedIn: https://www.linkedin.com/in/devansh-devansh-516004168/
My content:
Read my articles: https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Get a free stock on Robinhood. No risk to you, so not using the link is losing free money: https://join.robinhood.com/fnud75