
What is Concept Drift and how to Solve it
One of the biggest Problems in AI right now.

It takes time to create work that’s clear, independent, and genuinely useful. If you’ve found value in this newsletter, consider becoming a paid subscriber. It helps me dive deeper into research, reach more people, stay free from ads/hidden agendas, and supports my crippling chocolate milk addiction. We run on a “pay what you can” model—so if you believe in the mission, there’s likely a plan that fits (over here).
Every subscription helps me stay independent, avoid clickbait, and focus on depth over noise, and I deeply appreciate everyone who chooses to support our cult.
PS – Supporting this work doesn’t have to come out of your pocket. If you read this as part of your professional development, you can use this email template to request reimbursement for your subscription.
Every month, the Chocolate Milk Cult reaches over a million Builders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission)- https://forms.gle/Pi1pGLuS1FmzXoLr6
Thanks to their versatility, Neural Networks are a staple in most modern Machine Learning pipelines. Their ability to work with unstructured data is a blessing since it lets us allows us to partially -partially being important here- replace domain insight (expensive and hard to attain) with computational scale (cheaper and easier to attain).
However, turns out that blindly stacking layers and throwing money at problems doesn’t work as well as some people would like you to believe. There are several underlying issues with the training process that scale does not fix, chief amongst them being distribution shift and generalization. Neural Networks break when we give them inputs in unexpected ways/formats. For example, despite the impressive gains in LLM capabilities, this has been one of the most difficult parts for them to address-
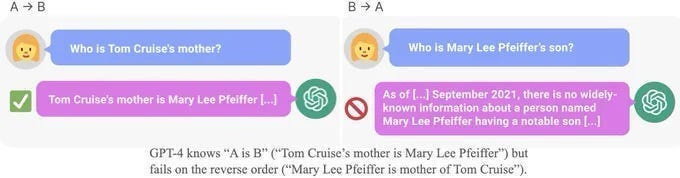
There are several ways to improve generalization such as implementing sparsity and/or regularization to reduce overfitting and applying data augmentation to mithridatize your models and to stop them being such delicate princesses. We will discuss them at length another time.
Today, we will discuss a root cause behind a lot of these problems and what causes it.
Executive Highlights (tl;dr of the article)
What is Distribution Shift: Distribution shift, also known as dataset shift or covariate shift, is a phenomenon in machine learning where the statistical distribution of the input data (features or covariates) changes between the training and deployment environments. This can lead to a significant degradation in the performance of a model that has been trained on a specific data distribution when it encounters data from a different distribution.

Possible Sources of Distribution Shift: Distribution shift can arise from various sources, including sample selection bias, where training data doesn’t reflect real-world distribution; non-stationary environments, where data changes over time; domain adaptation challenges, where models trained on one domain struggle in another; data collection and labeling issues; adversarial attacks; and concept drift, altering relationships between features and the target variable (this is something I dealt with when trying to build AI that sells loans to people).
Mitigating distribution shift: Good data + adversarial augmentation + constant monitoring works wonders. Some people try to use complex augmentation schemes, but this is pointless. Keep it simple- and throw in some random noise. Works really well. Also helps you avoid unnecessary complexity in your solutions.
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
Understanding Distribution Shift
I’m going to skip re-explaining what distribution shift is, since we already did it in the highlights and I believe in your intelligence. If you want extra help, take a look at a more traditional example of what a distribution shift looks like in AI-
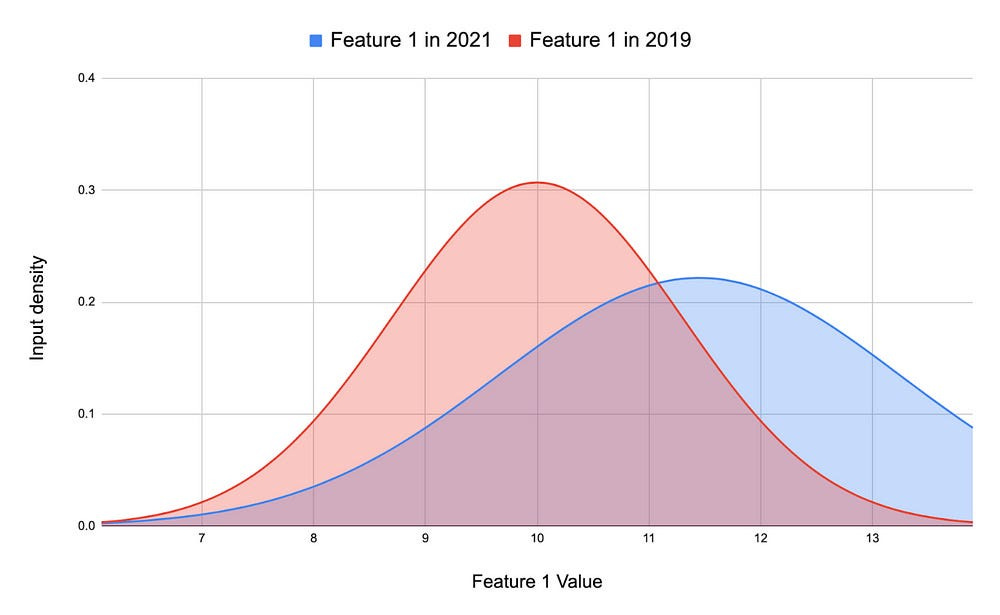
People can often underestimate how often and in how many ways shift can occur. Let’s work through some examples before covering how to fix it. Some of these will overlap with each other, but I’m keeping them separate to demonstrate the different perspectives one can take when addressing these challenges.
Sample Selection Bias
Sample selection bias occurs when the training data doesn’t accurately represent the real-world data distribution. This mismatch can lead to models that perform well on the training data but generalize poorly to real-world scenarios.
Example 1: Facial Recognition Systems and Demographic Bias:
A while back, there was a story of a SOTA Vision model that was meant to track a football during a match. However, it ended up tracking a referee’s bald head. I guess that the dataset didn’t have any top-angle pictures of bald people, causing it to get confused by the smoothness.

Example 2: Medical Diagnosis and Hospital-Specific Biases:
A disease prediction model trained on data from a specific hospital might not generalize well to patients from different hospitals or demographics. This is because medical practices, patient demographics, and even disease prevalence can vary significantly across different healthcare settings.
Non-Stationary Environments
In many real-world applications, data is not static. As the world changes, models trained on historical data might become less accurate as time progresses and the data distribution evolves.
Example 1: Financial Markets and Evolving Trends:
A stock prediction model trained on historical stock prices might become less accurate over time due to factors like evolving market dynamics, new regulations, or unforeseen global events.
Example 2: Language Models and Shifting Language:
Language Models trained on social media data need to adapt to constantly evolving language use, slang (I recently learned about the word “girl-dinner”), and emerging topics. Different generations might even completely change words (the word terrible has seen a large drift from its original meaning) or use different kinds of communications (one generation might be inspired by shows like Yes Minister and Silicon Valley to be more satirical). Not to mention that culture is always shifting b/c of interactions with over groups, which might cause new language patterns/changing rhetorical devices.
Domain Adaptation Challenges
Domain adaptation addresses the challenge of applying models trained on one domain (the source domain) to a different but related domain (the target domain). Even if the task remains the same, differences in data characteristics can significantly impact performance.
Example 1: Medical Image Segmentation — Different Modalities:
A model trained to segment tumors in brain MRI scans might not perform well when applied to CT scans of the brain. Although both modalities provide images of the brain, differences in imaging techniques and image characteristics require domain adaptation.
Example 2: Natural Language Processing — Reviews vs. Tweets:
A sentiment analysis model trained on product reviews might struggle with social media posts like tweets. The shorter length, informal language, and use of slang in tweets create a different domain compared to the more structured language of product reviews.
Adversarial Attacks: Deliberately Fooling the Model
Adversarial attacks involve intentionally crafting malicious input data to exploit vulnerabilities in machine learning models. These attacks aim to cause the model to make incorrect predictions, potentially leading to severe consequences.
Example 1: Image Recognition — Adversarial Noise:
Adding subtle, carefully crafted noise to an image can be imperceptible to humans but cause an image recognition system to misclassify it. For example, an attacker might make minor modifications to a stop sign image, causing a self-driving car’s vision system to misinterpret it.
The results show that 67.97% of the natural images in Kaggle CIFAR-10 test dataset and 16.04% of the ImageNet (ILSVRC 2012) test images can be perturbed to at least one target class by modifying just one pixel with 74.03% and 22.91% confidence on average. We also show the same vulnerability on the original CIFAR-10 dataset. Thus, the proposed attack explores a different take on adversarial machine learning in an extreme limited scenario, showing that current DNNs are also vulnerable to such low dimension attacks.
Example 2: Spam Detection — Evolving Spam Techniques:
Spammers constantly evolve their techniques to bypass spam filters. A spam detection model needs to adapt to these evolving tactics, such as using subtle misspellings or inserting hidden text, to remain effective. We are working on something similar for exploring the security of Multi-Modal AI and how adversarial hackers would be able to bypass any security checks there.
Example 3: Language Model Attacks:
Similar to Vision Models, we can attack language models to either jailbreak them- to undo the protections implemented through alignment or guardrails- or to have them spit out their training data. This usually involves playing with types of prompt injection, the most notable of which was Deepmind’s Poem Attack.

Concept Drift
Concept drift occurs when the underlying relationship between input features and the target variable changes over time. If we’re not careful, this leads to completely destroying old models.
Example 1: Credit Scoring — Evolving Economic Factors:
Factors that predicted high creditworthiness a few years ago might not hold true today due to changing economic conditions or consumer behavior. A credit scoring model needs to adapt to these evolving relationships to ensure fair and accurate assessments.Example 2: Recommender Systems — Shifting User Preferences:
Recommender systems rely on understanding user preferences, which can change over time. A model that recommends products based on past purchase history needs to adapt to evolving tastes and preferences to remain relevant.
How to Fix Distribution Shift
Fixing distribution shift revolves around the usual suspects-
Data Quality and Quantity: Ensure training data encompasses the variety expected in real-world deployment. On top of this, expand the training dataset by applying transformations (e.g., rotations, crops, color shifts) to existing data, improving robustness to variations. Some teams try to get too clever with Data Augmentation, implementing complex schemes to address the limitations of your dataset. You probably don’t need that. Before you decide to get too clever, consider the following statement from TrivialAugment-
Second, TA teaches us to never overlook the simplest solutions. There are a lot of complicated methods to automatically find augmentation policies, but the simplest method was so-far overlooked, even though it performs comparably or better
Lastly, you should remember that there is a lot of good in exploring different feature extractions to build richer representations of your data. That’s one of the best ways to improve model performance.
Ensemble Methods: Combine predictions from multiple models trained on different subsets of data or with different architectures to improve resilience to individual model biases.
Both the above work on the well known principle “Diversity is key in maintaining and improving AI performance.” Meta showed this wonderfully, in their publication “Beyond neural scaling laws: beating power law scaling via data pruning” where they use intelligent sample selection to overcome power-law scaling (big Neural Network needs BIG data to get 1% performance improvement) by picking data samples that add “information” to the existing sample- “Such vastly superior scaling would mean that we could go from 3% to 2% error by only adding a few carefully chosen training examples, rather than collecting 10x more random ones”

If you want to go back earlier, Google’s “Self-training with Noisy Student improves ImageNet classification” dropped conceived, believed, and achieved their way into becoming the top model on ImageNet using 12 times fewer images (3.5 Billion Additional Labeled images for their competitors vs 300 Million Unlabeled images for the big G; notice the savings in labeled vs unlabeled as well) by injecting noise to create a more diverse training dataset/model representation.
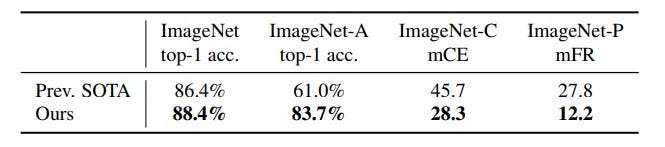
Continual Learning and Model Updates: Implement systems that continuously learn and adapt to new data, ensuring models remain relevant as data distributions evolve. Retraining gets expensive, which is another reason why simple models are king.
Robust Evaluation and Monitoring: Evaluate models on diverse datasets and monitor performance over time to detect and address potential distribution shifts.
This is a very nuanced field with a lot of veruy specific techniques, tradeoffs, etc; so I’m going to end this here. However, we will be doing deep dives into the different techniques and their various pros/cons in dedicated deep dives. One was covered below —

Thank you for being here, and I hope you have a wonderful day.
If you have a lot of money to burn, let’s just go to Vegas instead for Market Research
Dev ❤
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.
I regularly share mini-updates on what I read on the Microblogging sites X(https://twitter.com/Machine01776819), Threads(https://www.threads.net/@iseethings404), and TikTok(https://www.tiktok.com/@devansh_ai_made_simple)- so follow me there if you’re interested in keeping up with my learnings.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
https://machine-learning-made-simple.medium.com/
My YouTube: https://www.youtube.com/@ChocolateMilkCultLeader/
Reach out to me on LinkedIn. Let’s connect: https://www.linkedin.com/in/devansh-devansh-516004168/
My Instagram: https://www.instagram.com/iseethings404/
My Twitter: https://twitter.com/Machine01776819
This has definitely been an issue when I develop more complex projects.
Excellent post Devansh. Puts a finger on a very big problem. Can’t wait for a deep dive on drift, invarient truth, and LLM hallucinations.