
Why Redis is so Fast Part 1: The Historical Foundations
Inside the ruthless architectural decisions that made Redis one of the most predictably performant systems in modern computing

It takes time to create work that’s clear, independent, and genuinely useful. If you’ve found value in this newsletter, consider becoming a paid subscriber. It helps me dive deeper into research, reach more people, stay free from ads/hidden agendas, and supports my crippling chocolate milk addiction. We run on a “pay what you can” model—so if you believe in the mission, there’s likely a plan that fits (over here).
Every subscription helps me stay independent, avoid clickbait, and focus on depth over noise, and I deeply appreciate everyone who chooses to support our cult.
PS – Supporting this work doesn’t have to come out of your pocket. If you read this as part of your professional development, you can use this email template to request reimbursement for your subscription.
Every month, the Chocolate Milk Cult reaches over a million Builders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission)- https://forms.gle/Pi1pGLuS1FmzXoLr6
Recently I came across a short by the legendary ByteByteGo on why Redis is so speedy. It had some very interesting notes, so I decided to study them further to see what we can learn. (PS- If you don’t already follow him, do yourself a favor and follow Alex Xu , man never misses).
Redis’s speed wasn’t an accident — it was a product of engineering asceticism. This article is a deep dive into the original performance model that made Redis dominant: in-memory data, purpose-built data structures, and a single-threaded execution core.
While Redis has expanded dramatically in recent years — adding I/O threading, full-text search, JSON document support, and more — this piece focuses on the original three pillars of Redis’s architecture. It’s a historical lens through which we can understand not only what Redis was, but why it became the foundation for so many modern, high-performance systems. Future articles will explore the newer architectural expansions.
We’ll break Redis down across its three foundational pillars:
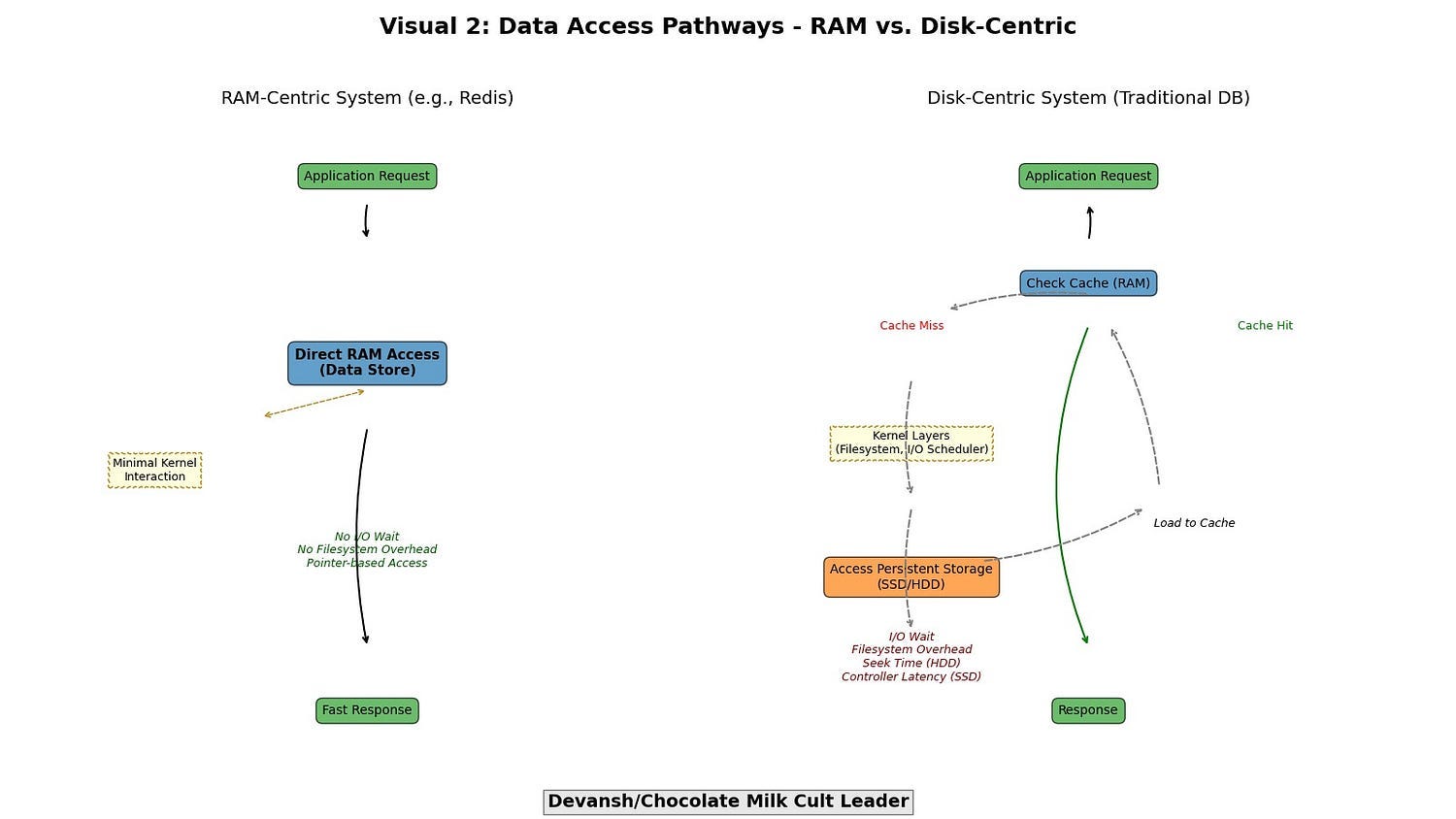
Operating primarily on data in ultra-fast RAM.
Using data structures meticulously designed for in-memory efficiency and specific access patterns.
A single-threaded command processing model that, when combined with I/O multiplexing, elegantly sidesteps the common pitfalls of multi-threaded contention for its typical workload.
Let’s explore each of these in more detail.
Executive Highlights (TL;DR of the Article)
This deep dive dissects the three core architectural pillars responsible for its legendary speed, stripping away hype to reveal hard engineering choices:
RAM-Resident Obligation: Fundamentally, Redis operates with its active dataset exclusively in Random Access Memory. This isn’t a caching layer; it’s the primary datastore. The orders-of-magnitude latency advantage of RAM over any persistent storage (SSD/HDD) forms the bedrock of its responsiveness.
Hardware-Sympathetic Data Structures: Beyond just being “in-memory,” Redis employs custom-engineered data structures (like Simple Dynamic Strings, Skip Lists, and memory-adaptive encodings such as Listpacks). These are not textbook abstractions but are purpose-built to maximize CPU cache utilization, minimize pointer indirection penalties, and align with the granular realities of memory access patterns.
Single-Threaded Command Core with I/O Multiplexing: Counter-intuitively, Redis processes client commands primarily using a single thread. This design, coupled with non-blocking I/O and efficient event multiplexing (e.g., epoll, kqueue), eradicates the crippling overhead of lock contention common in multi-threaded systems for shared data access, while still efficiently servicing thousands of concurrent client connections.
Predictable under pressure: No slow path. No degradation curve. So long as your dataset fits in RAM and your commands are scoped, Redis remains fast — regardless of connection count or operation volume.
Redis has continued to evolve beyond this original model. Notable additions in Redis 6 and 7 include:
Optional I/O threading for network scalability
Redis Stack modules like RediSearch, RedisJSON, and RedisTimeSeries
Server-side functions, observability upgrades, and multi-model query support
Redis 7.0’s listpack migration (replacing ziplist) for improved memory efficiency
Clustering and persistence optimizations for enterprise deployments
These additions don’t replace the core model described below — they build on it. This article is part 1 of a series; future installments will explore these advanced layers.
We’re going to break down each of these foundational pillars in great detail.
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
Pillar 1- The Primacy of RAM: Eliminating Disk Latency at the Root
Why design around RAM?
You eliminate I/O wait altogether. No seek time. No filesystem overhead. You bypass entire layers of the kernel. This makes RAM not just faster — but qualitatively different as a dresign substrate.
Let’s understand that in more detail-
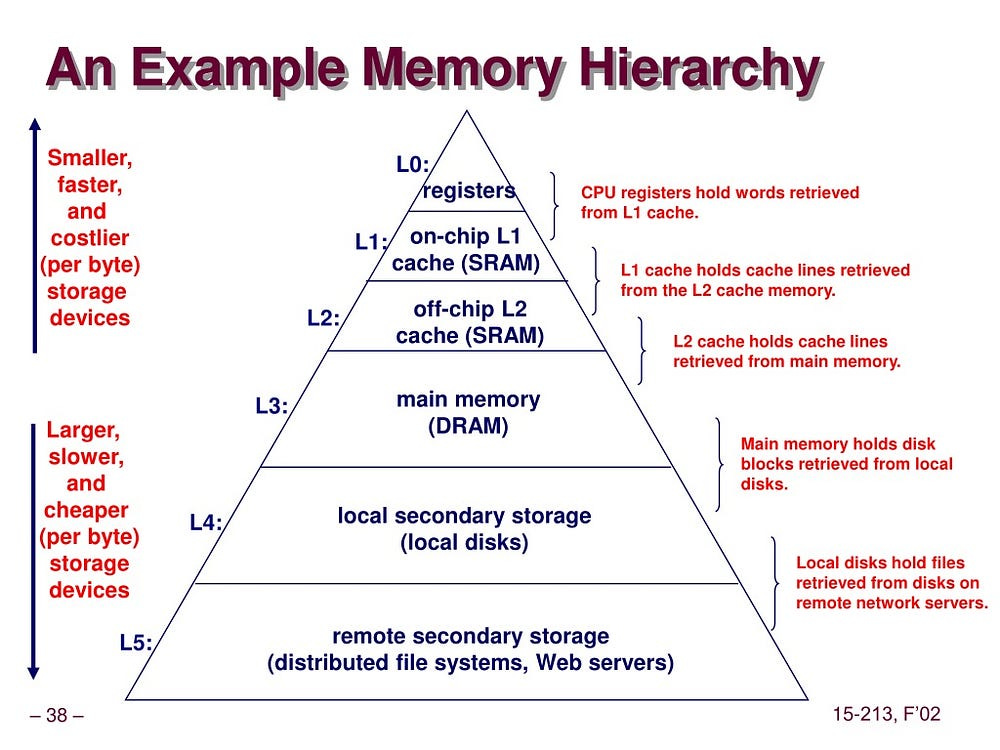
Consider the memory hierarchy, a pyramid of speed and cost:
CPU Registers & Caches (L1/L2/L3): Nanoseconds. Data here is practically an extension of the CPU’s execution units.
RAM (Main Memory): Tens to hundreds of nanoseconds. Composed of semiconductor cells (DRAM), directly addressable by the CPU via a high-bandwidth memory bus. Access is purely electronic, incredibly fast relative to persistent storage.
Solid State Drives (SSDs): Tens to hundreds of microseconds. Flash memory cells. While vastly faster than HDDs, they involve more complex controller logic, I/O bus protocols (NVMe, SATA), and inherently slower state-change physics than DRAM. A significant leap in latency from RAM.
Hard Disk Drives (HDDs): Milliseconds. The realm of mechanical action — spinning platters, seeking read/write heads. The latency here is dominated by physical movement, orders of magnitude slower than RAM.
Redis, by placing its active dataset squarely in RAM, confines its critical read/write operations to the nanosecond domain. Traditional disk-backed databases, even with sophisticated caching, eventually contend with the latency penalties of SSDs or HDDs. Their caches are layers above persistent store; for Redis, RAM is the store for active data.

This choice has profound implications:
Minimal Access Latency: Operations are not gated by disk I/O. The speed of light and electron movement within silicon are the primary constraints, not mechanical inertia or slower flash cell programming.
Simplified Data Manipulation: Data structures can be designed assuming direct, pointer-based access, without the indirection and serialization/deserialization overhead required for on-disk formats or inter-process communication with a separate cache process.
The Inescapable Tradeoff: Volatility and Volume
RAM’s speed comes at the price of volatility (data loss on power failure) and higher cost per gigabyte compared to persistent storage. Redis acknowledges this directly:
Persistence Mechanisms (RDB Snapshots, AOF Logs): These are crucial for durability but are intentionally designed to operate asynchronously or in background threads. They are for recovery, not for serving the primary, latency-sensitive operational workload. The hot path for reads and writes remains unsullied by disk I/O.
Dataset Size Limitation: The working set is constrained by available RAM. This forces a discipline: Redis is not a data lake; it’s a high-octane reservoir for data that demands immediate access.

This isn’t a compromise; it’s a strategic focus. Prioritize speed for the active dataset above all else, and handle durability as a distinct, non-interfering concern. You cannot architect Redis as a general-purpose store with eventual access latency. The design forces you to accept RAM constraints — but in return, gives deterministic, low-latency ops as baseline behavior.
Pillar 2: Data Structures — Algorithmic Efficiency Forged in Memory
Designing for RAM doesn’t just remove disk latency. It changes what’s possible. With disk out of the equation, a system no longer has to optimize for block I/O, page faults, or seek alignment. Instead, Redis structures are tuned to exploit direct addressing, low-level CPU behavior, and memory locality.
This demands a radical rethinking of structural design:
CPU Cache Latency: The chasm between L1/L2/L3 cache access (nanoseconds or fractions thereof) and main RAM access (tens to hundreds of nanoseconds) becomes paramount. Structures must be cache-cognizant.
Pointer Indirection Penalties: Each pointer dereference, especially if it leads to a cache miss, is a stall. Structures overly reliant on scattered, multi-hop pointer chasing bleed performance.
Memory Allocation & Fragmentation: The overhead of malloc/free and the impact of memory fragmentation on locality cannot be ignored in a high-throughput system.
The Specter of (Avoided) Lock Contention: While Redis’s core command processing is single-threaded (Pillar 3), the design of its structures often reflects a simplicity that would also benefit concurrent access patterns by minimizing shared mutable state, were that the primary model.
We need to build for RAM’s distinct access profile so that we can get for CPU-local execution, and for the unrelenting pursuit of ultra-low-latency responsiveness.
Let’s understand how.
RAM is Fast, But Not Flat: The Nuance of Memory Access
To comprehend Redis’s structural engineering, one must internalize a crucial truth:
RAM is exceptionally fast, yet its performance landscape is not uniform. Accessing data in RAM is not a singular, flat-cost operation.
Invisible performance cliffs and advantageous terrains define this landscape:
Sequential Access (The Preferred Path): Accessing contiguous memory locations (e.g., iterating an array) is maximally cache-friendly. CPU prefetchers excel here, aggressively pulling subsequent data blocks into cache lines before they are explicitly requested by the program. This effectively masks main memory latency, making sequential access appear almost as fast as cache access.
Random Access (The Costly Deviation): Accessing memory locations scattered unpredictably across RAM frequently results in CPU cache misses. Each miss forces the CPU to stall for hundreds of cycles, waiting for data to be fetched from main memory. This is the dominant cost in many naive RAM-based algorithms.
Pointer Chasing (The Prefetcher’s Nemesis): Following chains of pointers (e.g., traversing a linked list or a tree with disparate nodes) represents an indirect, non-linear memory traversal. This pattern fundamentally undermines CPU prefetching capabilities, as the next memory location is data-dependent and cannot be predicted. Each hop in a pointer chain risks a cache miss and its associated latency penalty.
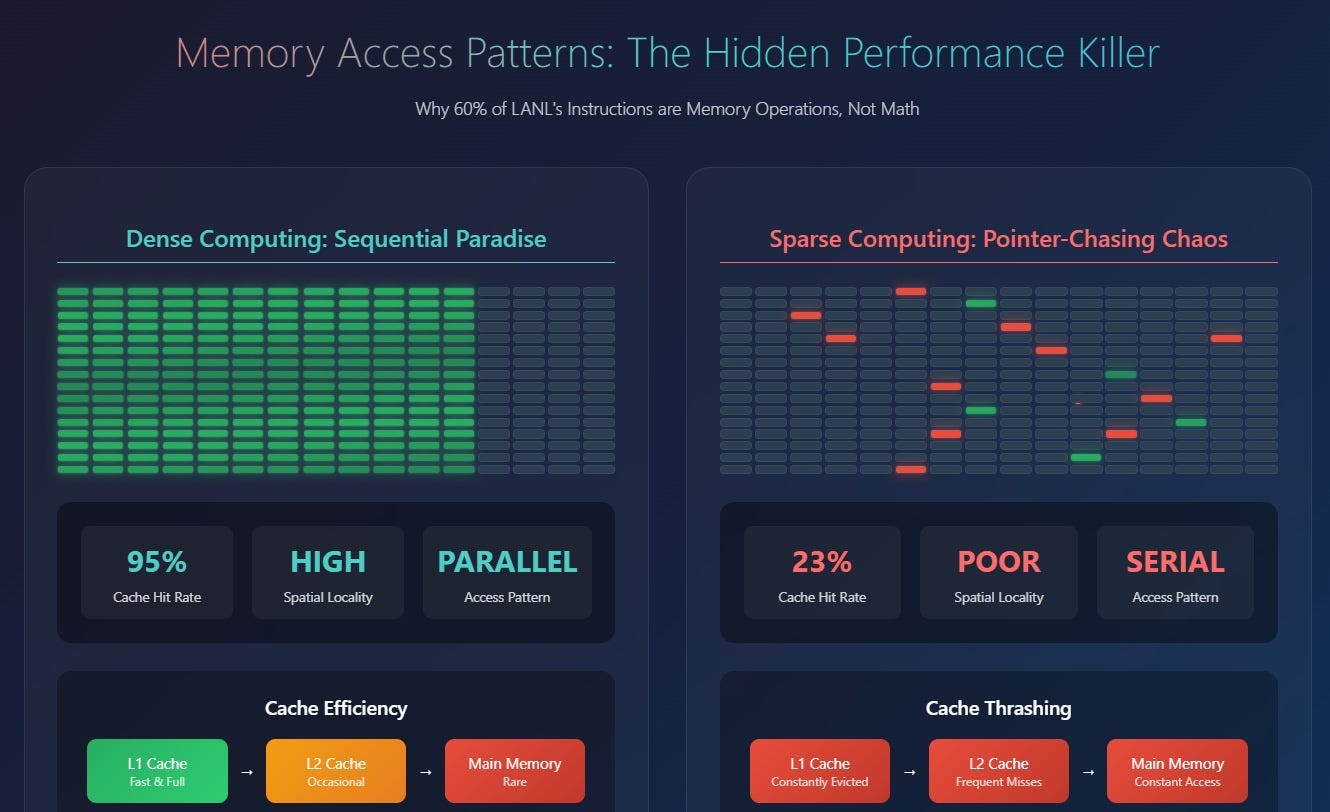
Designing high-performance data structures for RAM, therefore, transcends mere asymptotic algorithmic complexity (O(log N), O(1)). It becomes an exercise in optimizing memory access patterns: maximizing predictability and locality, minimizing random accesses, and ruthlessly curtailing pointer indirection. Redis’s core structures are a testament to this principle. It picks data structures that allow the following-
Minimal pointer indirection
Tight memory layout
Simplicity under high load
Amortized complexity management
Predictable degradation and graceful upgrade paths
Let’s take open step by step.
Hash Tables: O(1) Access Engineered for Minimal Coordination and Predictable Latency
The hash table is the workhorse of Redis, underpinning its fundamental key-value access model, which dominates typical workloads. Redis does not merely use hash tables; it employs a highly optimized implementation attuned to the demands of an in-memory, low-latency system.

Core Design Imperatives & Their Rationale:
O(1) Expected Time Complexity: Achieved through well-distributed hash functions and collision resolution via chaining (each bucket points to a linked list of entries that hash to the same slot). Chaining is preferred over open addressing schemes (like linear probing) because:
More Predictable Memory Layout: Chained entries for a bucket can often maintain better locality.
Simplified Deletion: Deletion in chained hash tables is straightforward.
Graceful Performance Degradation: Performance degrades more gracefully as the load factor increases, compared to some open addressing schemes that can suffer from clustering.
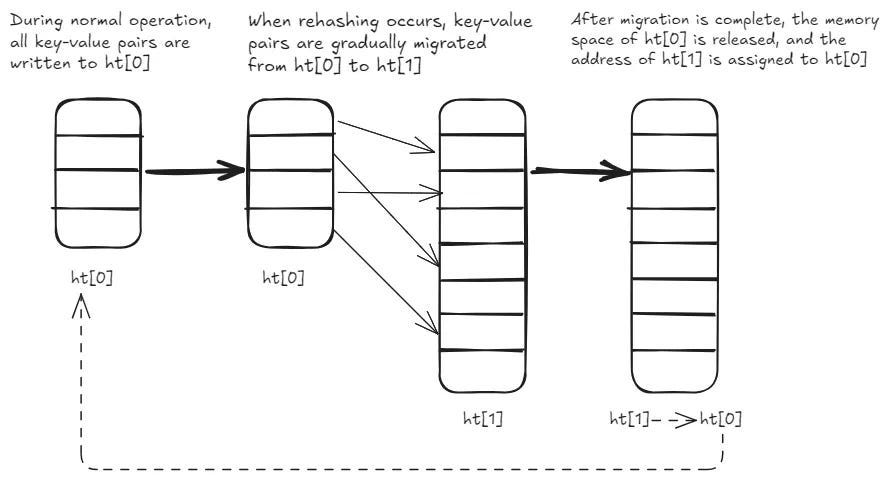
Incremental Rehashing — The Latency Smoother: As a hash table grows, it must be resized to maintain its O(1) access characteristics and prevent collision chains from becoming excessively long. A naive, “stop-the-world” rehash, where all entries are moved to a new, larger table in one go, would introduce unacceptable latency spikes, freezing the server.
Redis implements incremental rehashing:
Two hash tables (old and new) exist during the rehashing phase.
New writes always go to the new table. Reads check the old table first, then the new if not found.
Crucially, with each command processed (or on a timer basis), a small number of buckets are migrated from the old table to the new.
This distributes the significant cost of rehashing across many small, almost imperceptible steps, ensuring the main thread remains responsive. This design is elegant and effective precisely because the single-threaded command execution model eliminates the need for complex inter-thread synchronization during this sensitive structural transformation.
The process is visualized below-
Performance in the RAM Context:
In-memory hashing itself avoids the page faults and disk seek penalties that would plague a disk-backed hash table.
The small, typically shallow, collision chains keep pointer hops to a minimum during lookups, preserving cache locality where possible.
Incremental rehashing ensures that the critical path for client requests is not stalled by internal maintenance operations.
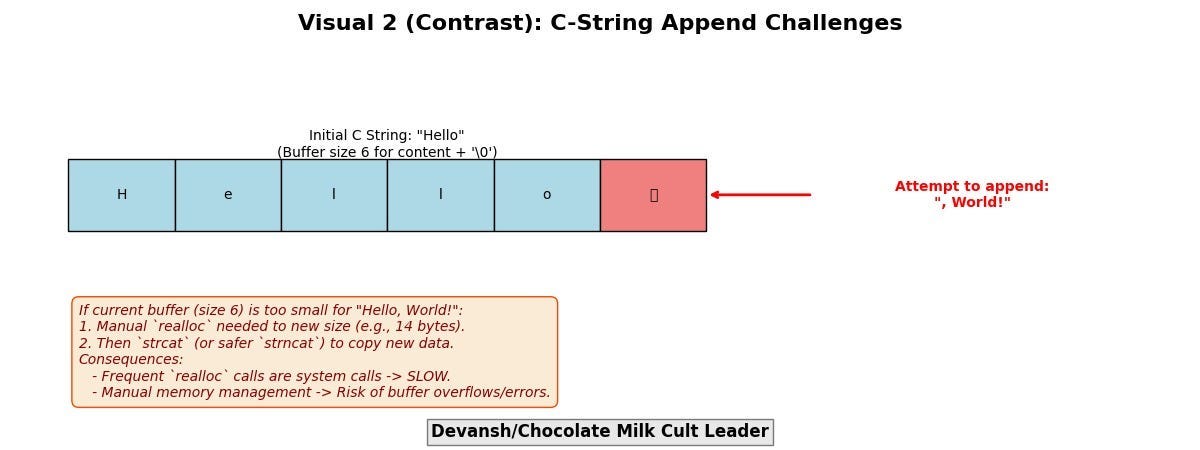
SDS (Simple Dynamic Strings): Binary Integrity and O(1) Length Without Scans
The standard C language null-terminated string (char *) is a relic ill-suited for high-performance, system-level programming due to fundamental inefficiencies and safety concerns:
O(N) Length Calculation (strlen): Requires a full scan to find the null terminator, burning CPU cycles and polluting caches, especially for frequently accessed or modified strings.
Costly Modifications: Appends or modifications often necessitate realloc, a system call with inherent overhead, and careful manual memory management to avoid buffer overflows or leaks.
Binary Unsafe: Incapable of storing arbitrary byte sequences containing null characters, limiting their use for generic binary data.
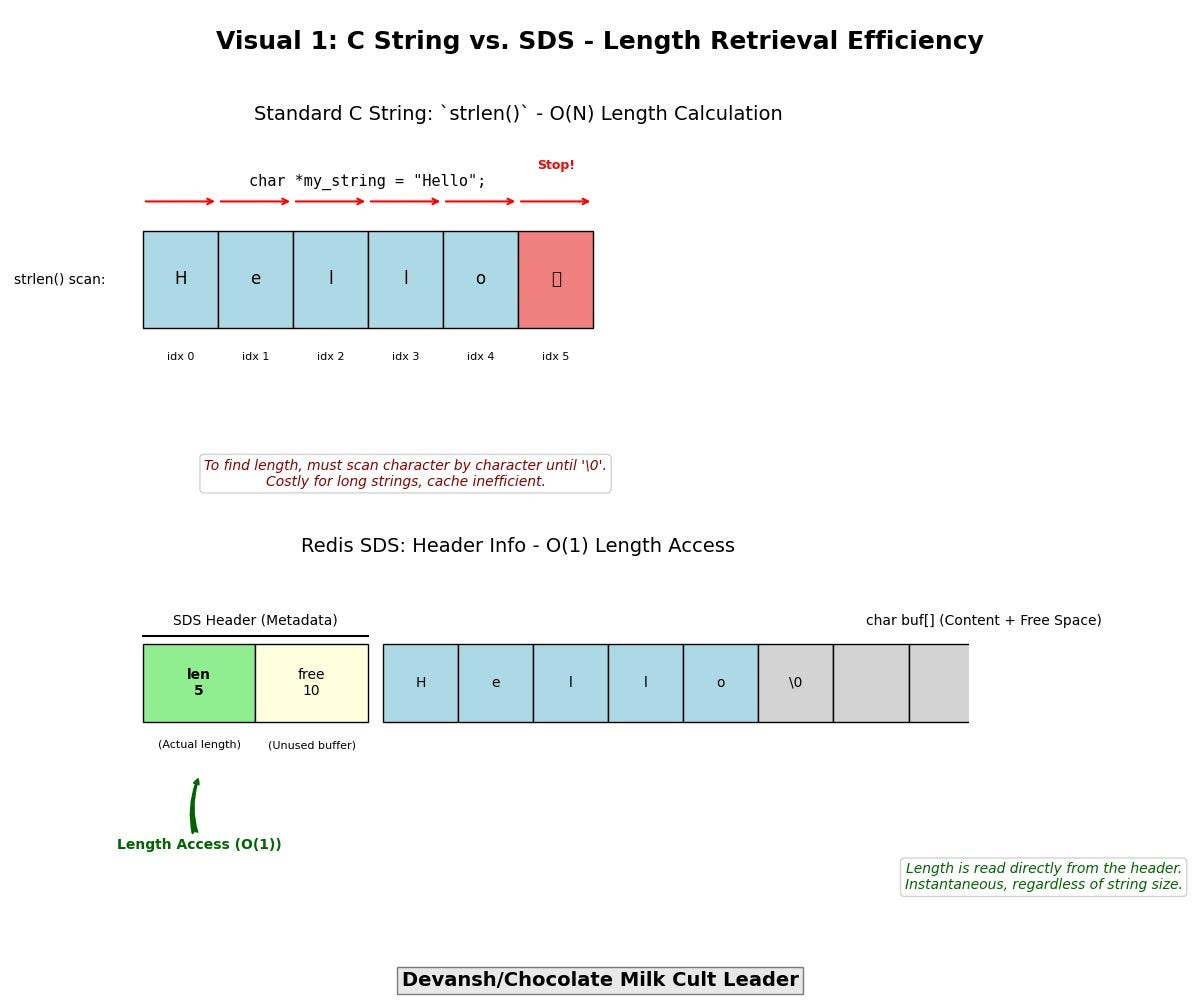
Redis’s SDS (Simple Dynamic String) — A Purpose-Built Alternative:
SDS is the default internal string representation in Redis, engineered to eradicate these deficiencies:
Explicit Length Storage (O(1) Access): An SDS string embeds its length (and allocated buffer size) directly within its structure (typically in a header preceding the character array). Retrieving the string’s length is an O(1) operation, eliminating costly scans.
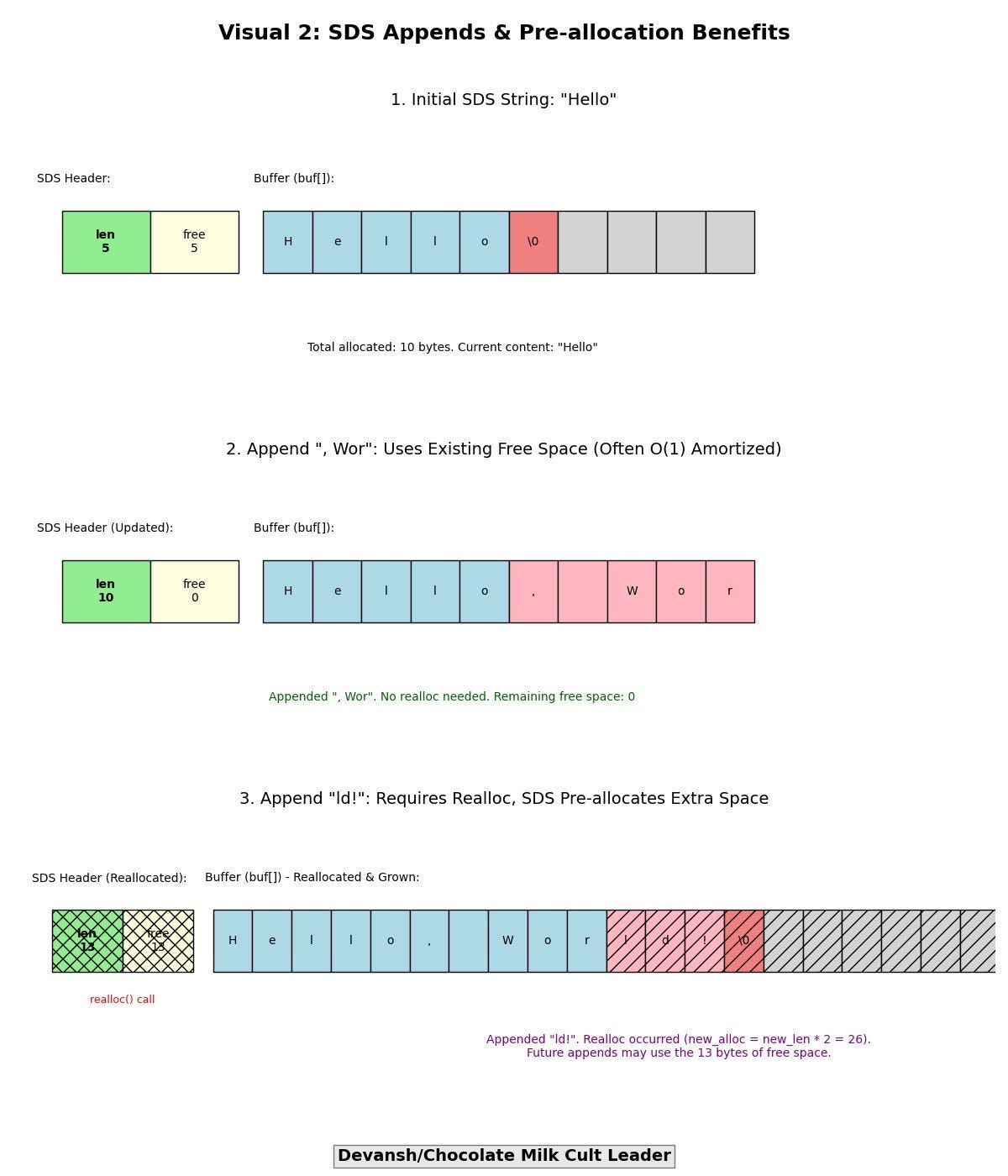
Amortized Append Costs via Pre-allocation: When an SDS string needs to grow, Redis often allocates more space than immediately required (e.g., doubling the new length, up to a certain maximum). Subsequent appends can then utilize this “free” space within the existing buffer, often making appends an O(1) amortized operation by deferring expensive realloc calls.
Binary Safety: Since length is explicit and not reliant on a null terminator, SDS strings can safely store any sequence of bytes, including embedded nulls. This makes them suitable for representing any kind of data, from text to serialized objects.

SDS is a pragmatic, low-level optimization critical for high-throughput string manipulations, minimizing CPU overhead and memory management churn in Redis’s most common operational paths.

Skip Lists: O(log N) Search with Cache-Friendly Linear Traversal Characteristics
For its Sorted Sets (ZSETs), which require efficient management of elements ordered by score, Redis deliberately eschews conventional balanced binary search trees (e.g., Red-Black Trees, AVL Trees).
While these structures offer the canonical O(log N) complexities for search, insertion, and deletion, their performance in high-performance, RAM-centric systems is often compromised by their interaction with CPU memory hierarchies:
Poor Cache Locality: Tree nodes are often allocated disparately in memory. Traversal and, particularly, rebalancing operations (rotations, color flips) involve chasing pointers across potentially non-contiguous memory regions, leading to frequent cache misses.
Expensive Rebalancing: The complex logic required to maintain tree balance after insertions or deletions involves significant pointer manipulation and conditional logic, incurring both computational overhead and further cache disruption.
Deep Pointer Chains: Operations can involve traversing deep chains of pointers, each hop risking a cache miss and a CPU stall.
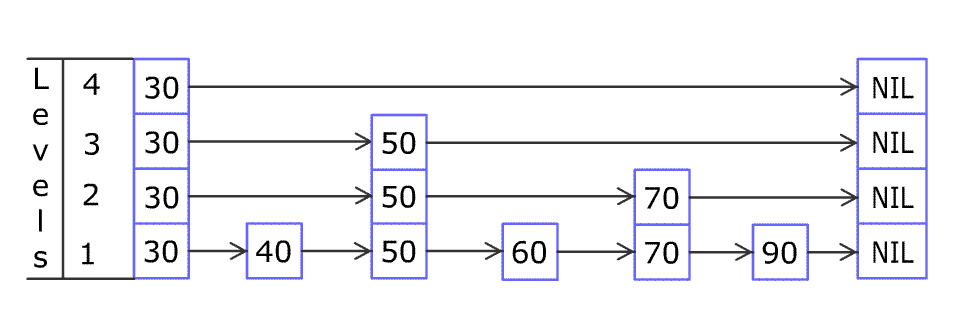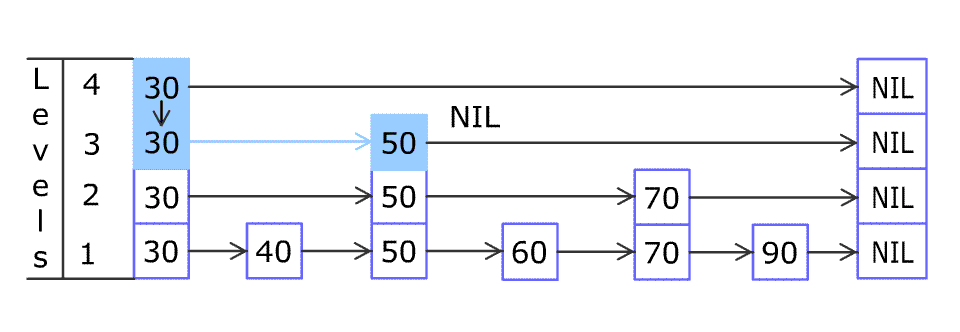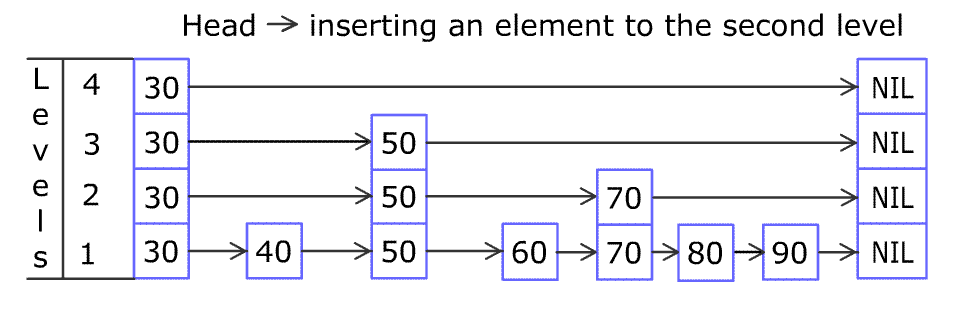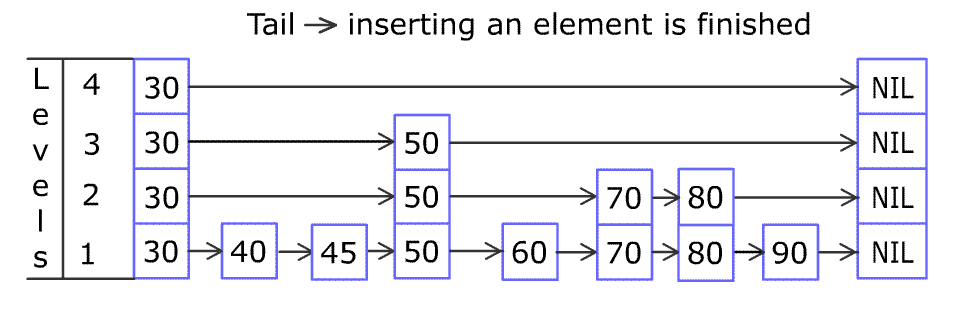
A skip list is a probabilistic data structure that provides O(log N) average-case performance for search, insertion, and deletion.

It uses a structural design inherently more sympathetic to RAM access patterns:
Layered Structure: Composed of multiple levels of sorted linked lists. Each node is randomly assigned a “level” during insertion; a node at level k possesses k forward pointers, allowing it to “skip” over several subsequent nodes in the layers below it. The highest levels act as sparse “express lanes.”
Search Mechanism: Traversal begins at the highest level of a header node. The algorithm moves forward along the current level as long as the next node’s score/key is less than the target. If the next node overshoots or is null, it drops down one level and repeats, progressively refining the search.
Why Skip Lists Excel in the RAM Context:
Enhanced Cache Coherence through Predominantly Linear Traversal: While traversing a skip list involves vertical drops between levels, movement within a level is linear. This pattern is significantly more predictable for CPU prefetchers than the scattered access of tree nodes. Prefetchers can often successfully pull subsequent nodes of a level into cache lines before they are explicitly accessed, masking main memory latency.
Absence of Complex, Global Rebalancing: Balance is achieved probabilistically by the random assignment of levels. There are no expensive, global rebalancing operations like tree rotations. Insertions and deletions have a more localized impact, reducing the scope of memory modification and cache invalidation.
Reduced Algorithmic Complexity and Pointer Manipulation: The core logic for skip list operations is generally simpler and involves less intricate pointer arithmetic than that of self-balancing trees. This can translate to fewer instructions and potentially fewer branch mispredictions.
In the unforgiving environment of RAM-centric, low-latency systems, these “micro-architectural” advantages often outweigh abstract asymptotic similarities. Redis’s skip lists deliver predictable O(log N) performance without the severe cache-thrashing penalties and rebalancing overheads that can plague tree-based implementations. This choice epitomizes the principle of engineering for the specific characteristics of the execution environment.
Memory-Adaptive Structures: Ziplist, Intset, Listpack — Dynamic Optimization for Small Data
Redis further demonstrates its commitment to memory efficiency by using adaptive representations for small data structures. It recognizes that employing full-fledged, pointer-heavy structures for collections containing only a few small elements is wasteful.
Ziplist (Legacy, but Illustrative): A specially encoded, doubly linked list stored as a single, contiguous block of bytes. It minimizes pointer overhead by encoding entry metadata (like previous entry length and current entry length/type) and values directly within this block. Traversal is O(N) (linear scan), but for very small N, the extreme compactness and excellent cache locality make it faster than a traditional linked list with its pointer dereferences.


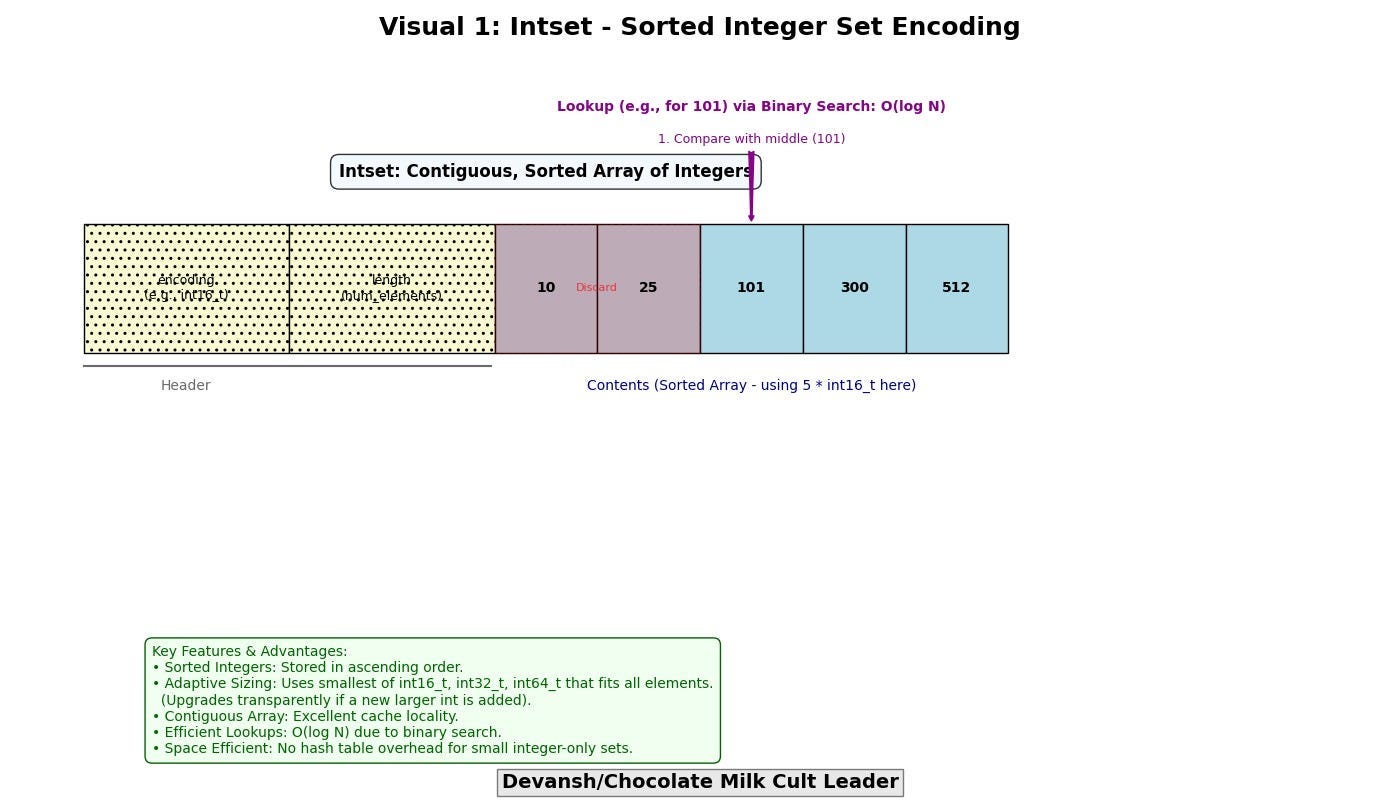
Intset: A specialized encoding for sets composed entirely of integers. It stores the integers sorted in a contiguous array, using the smallest integer type (int16_t, int32_t, int64_t) capable of holding all elements. Lookups utilize binary search (O(log N)). This avoids the overhead of a full hash table (pointers, bucket array, entry structures) for small sets of integers.
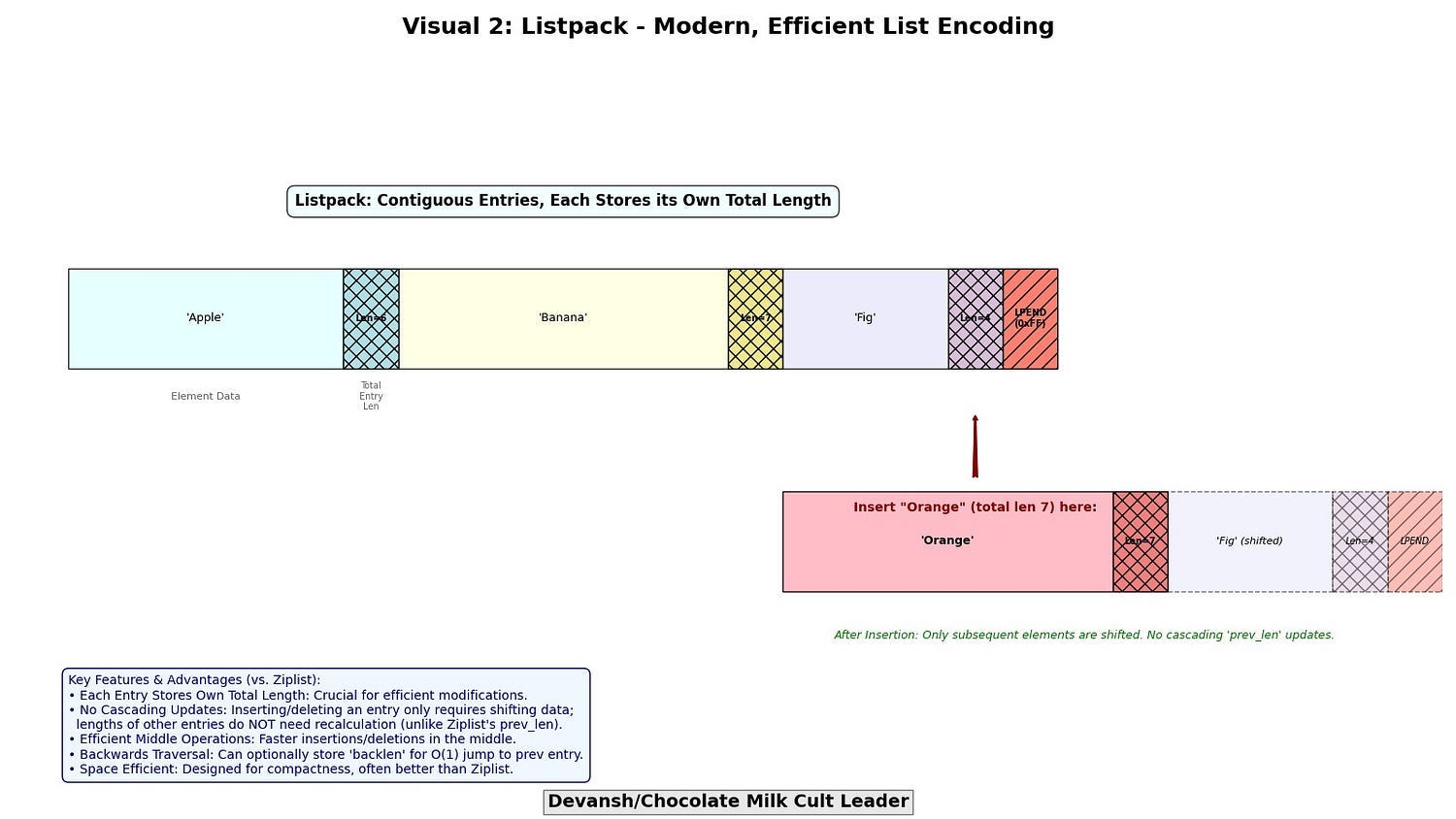
Listpack (Modern Successor to Ziplist): Addresses some of Ziplist’s limitations (e.g., cascading updates on insertion/deletion in the middle, which Ziplist suffered from due to needing to update ‘previous length’ fields). Listpack stores entries with their own length, making insertions and deletions more efficient without requiring updates to adjacent elements beyond shifting data. It’s designed for even better space efficiency and performance for small lists and hashes.
A critical feature here is transparent upgrading: When these memory-optimized structures grow beyond predefined size or content thresholds (e.g., a Ziplist exceeds a certain byte size, an Intset has too many elements, or a non-integer is added to an Intset), Redis automatically and transparently converts them into their more general-purpose, but less memory-dense, counterparts (e.g., a Ziplist representing a hash might convert to a standard hash table; a Listpack representing a list might convert to a quicklist, which is a linked list of Listpacks).
This dynamic structural adaptation ensures:
Minimal Memory Footprint for Small Data: Counters, short lists, small sets, and small hashes consume exceptionally little memory.
No Performance Cliff or Developer Intervention: The system gracefully scales the internal representation as data grows, without requiring explicit developer action or suffering an abrupt performance degradation.
This embodies a core Redis tenet: data structure selection is not static but dynamically responsive to operational scale and data characteristics.
The Overarching Principle: Trading Memory Generality for Operational Precision
Databases designed primarily for disk-based persistence often adopt uniform storage abstractions. The significant latency of disk I/O tends to dominate other performance factors, and uniformity can simplify caching layers, serialization, and on-disk layout management.
Redis, having vanquished the disk I/O bottleneck by operating in RAM, inverts this philosophy:
Since all active data resides in fast, directly addressable RAM, the overheads of CPU cache misses, pointer indirections, and inefficient memory access patterns become the new primary adversaries.
Consequently, each data structure can, and must, be highly specialized and optimized for its intended use case and the specific access patterns it will encounter.
Every design choice is workload-aware, prioritizing the reduction of CPU cycles and the maximization of cache utilization.
In other words, Redis is fast because its very DNA, its data structures, are conceived and engineered for memory, anticipating and mitigating the nuanced performance characteristics of modern CPU and RAM architectures. Each byte, each pointer, each traversal is a deliberate decision in a relentless campaign against latency.
This is what it looks like when system architecture is designed not to chase feature parity — but to dominate a narrow, high-pressure operational regime.
Pillar 3: The Single-Threaded Command Processor — Conquering Concurrency with Brutal Simplicity
We’ve already examined the first two pillars of Redis’s performance architecture: in-memory operation and data structures optimized for RAM. Now we turn to the third — and most misunderstood — pillar: its single-threaded command execution model.
In an industry obsessed with parallelism and multi-core scaling, Redis makes a heretical move: it processes all client commands on a single thread.
At first glance, this looks like a performance handicap. In reality, it’s one of the most strategically precise decisions in systems design.

Multi-Threaded Servers Are Not Free
More threads don’t mean more speed. They mean more coordination, and coordination is expensive.
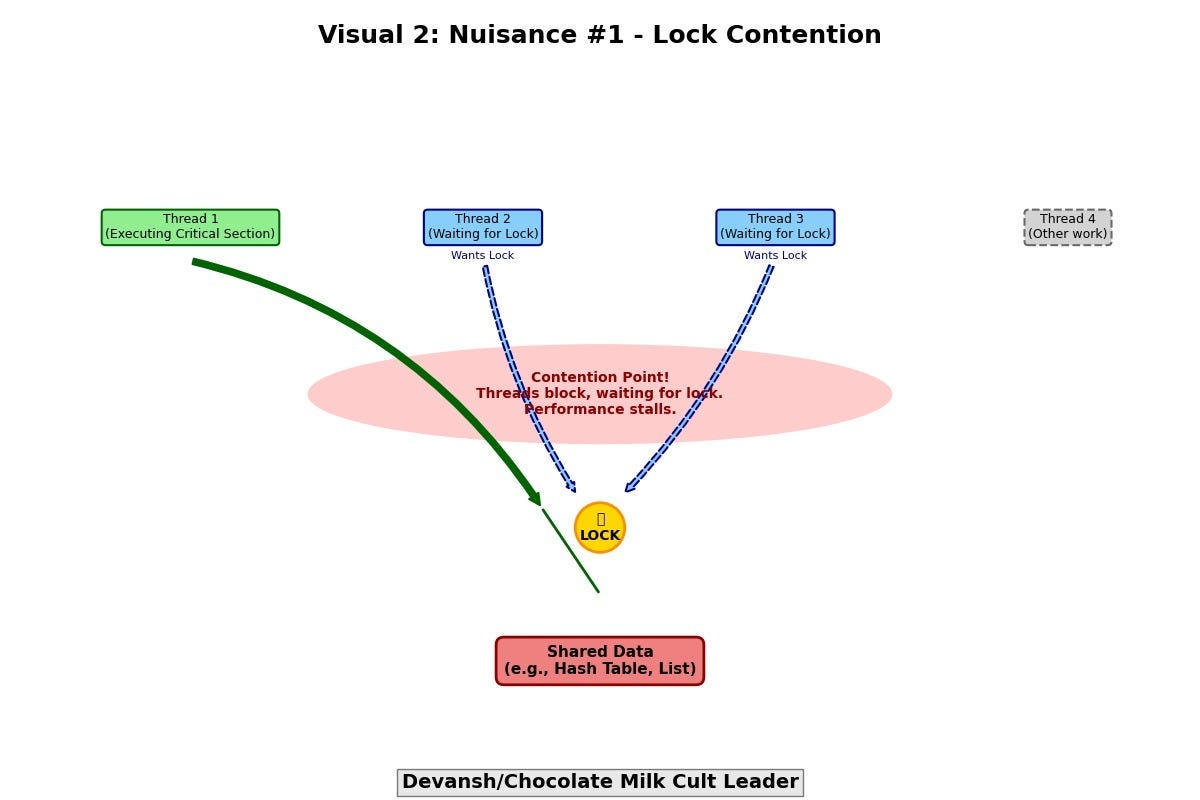
Nuisance#1: Lock Contention
In a traditional multi-threaded server:
Threads share memory.
Shared memory requires locks to avoid race conditions.
Locks introduce overhead — even uncontended.
Worse, they introduce waiting.
As concurrency increases, threads start blocking each other. Performance plateaus or collapses, not due to CPU exhaustion, but because threads are waiting on locks. Even more insidious: long-held locks can cause convoying, where queues of threads sit idle behind a single blocked thread.
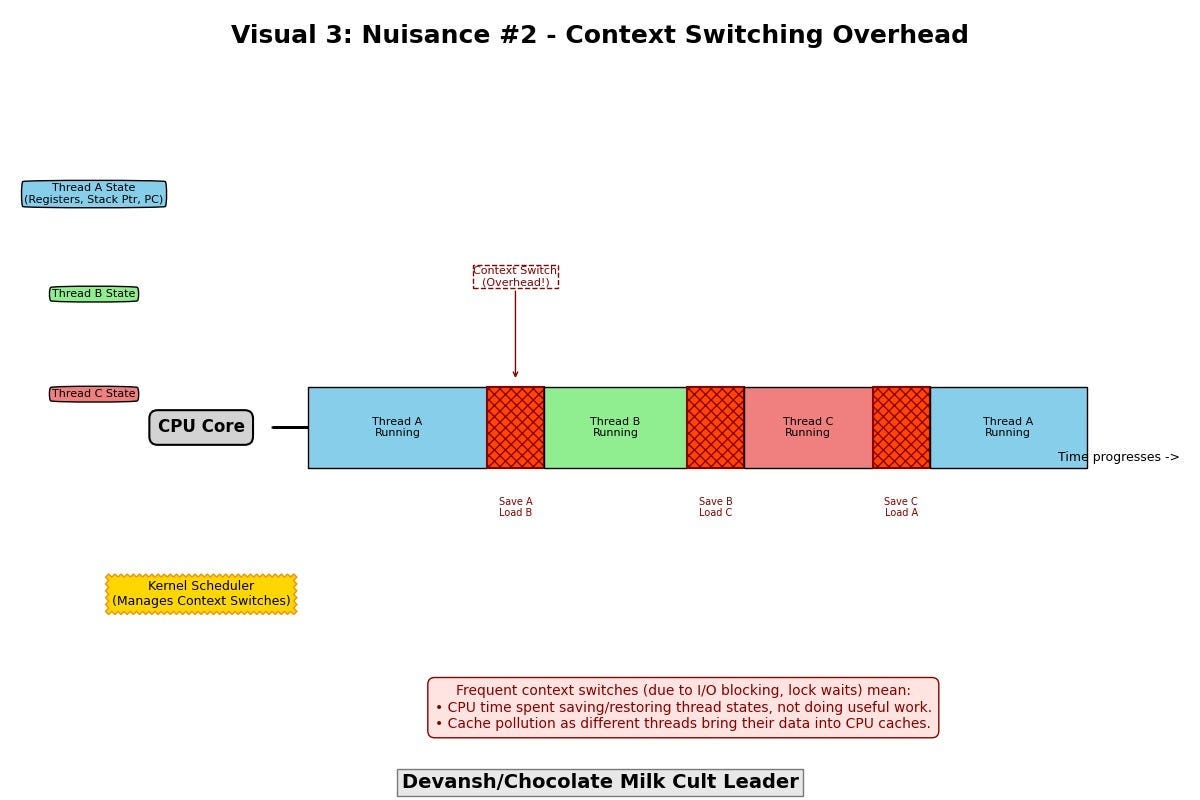
Problem #2: Context Switching
The kernel must save and restore state as threads are swapped on and off cores:
Registers
Stack pointers
Program counters
When threads block on I/O or wait for locks, context switches spike. That’s overhead your application doesn’t control — and doesn’t benefit from.
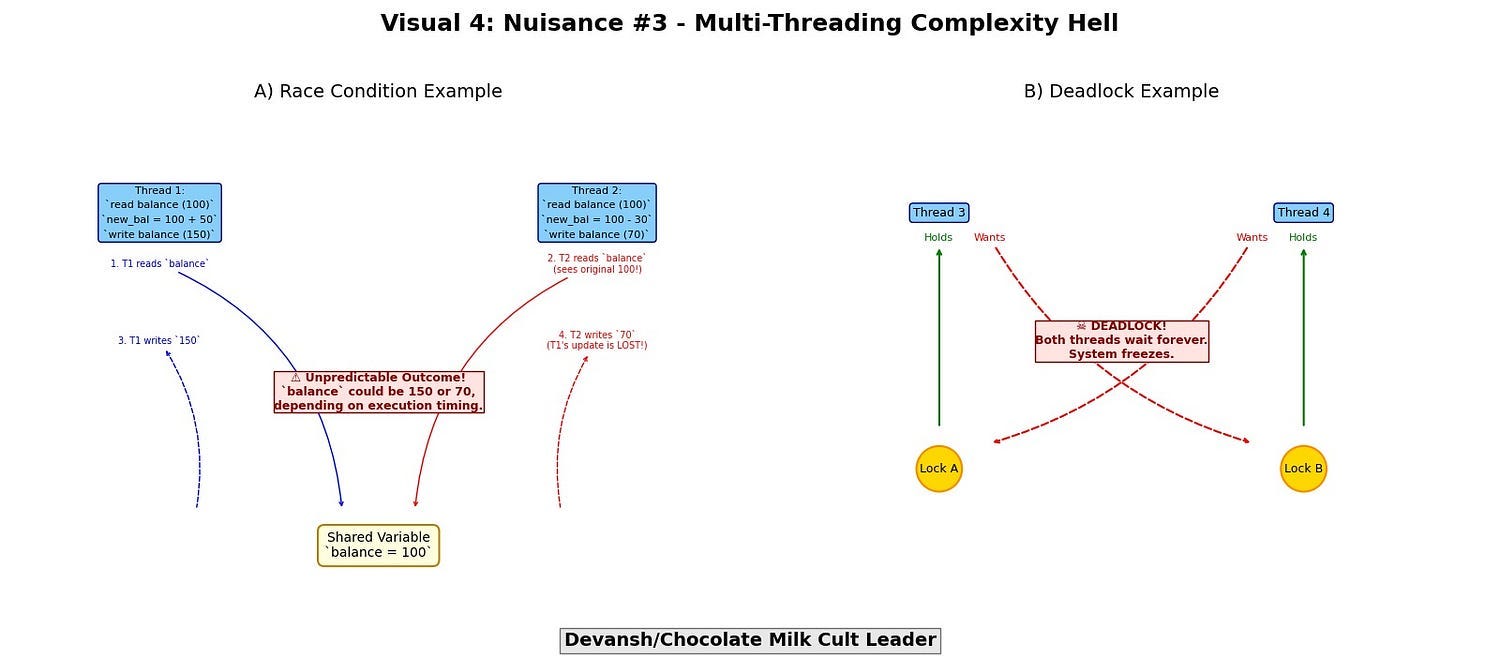
Problem #3: Complexity Hell
Multi-threaded code isn’t just harder to write. It’s harder to reason about:
Race conditions: unpredictable, non-deterministic bugs
Deadlocks: threads waiting on each other forever
Livelocks: infinite motion, zero progress
False sharing: cache lines invalidated by unrelated writes
This isn’t theoretical. It shows up in production in the form of flaky performance, elusive bugs, and operational instability.
Redis’s Answer: One Thread, No Locks
Redis takes a position very few systems dare to:
If your workload is fast enough, you don’t need parallelism — you need clarity.
Here’s how Redis Executes Commands-
All client commands are executed sequentially, on one thread.
This thread owns the entire in-memory dataset.
There is no shared memory, no mutexes, no atomic primitives.
This means every command executes with implicit atomicity. No other command can mutate state during execution. That makes Redis:
Deterministic
Race-free
Lockless by design
And because Redis’s operations are already fast (hash lookups, list pushes, SDS appends), the CPU isn’t the bottleneck. The work is short; concurrency only introduces drag.
But How Does Redis Handle Thousands of Clients?
This is where the architecture gets elegant.
The Enabler: Non-Blocking I/O + Event Loop
Redis doesn’t spawn a thread per client. It doesn’t block on sockets. Instead, it uses:
Non-blocking I/O- In traditional blocking I/O, if a thread attempts to read from a socket that has no data available, or write to a socket whose send buffer is full, the thread will block (sleep) until the operation can complete. In a thread-per-connection model, this is manageable (though resource-intensive). For a single-threaded server, blocking I/O on one connection would freeze all other connections.
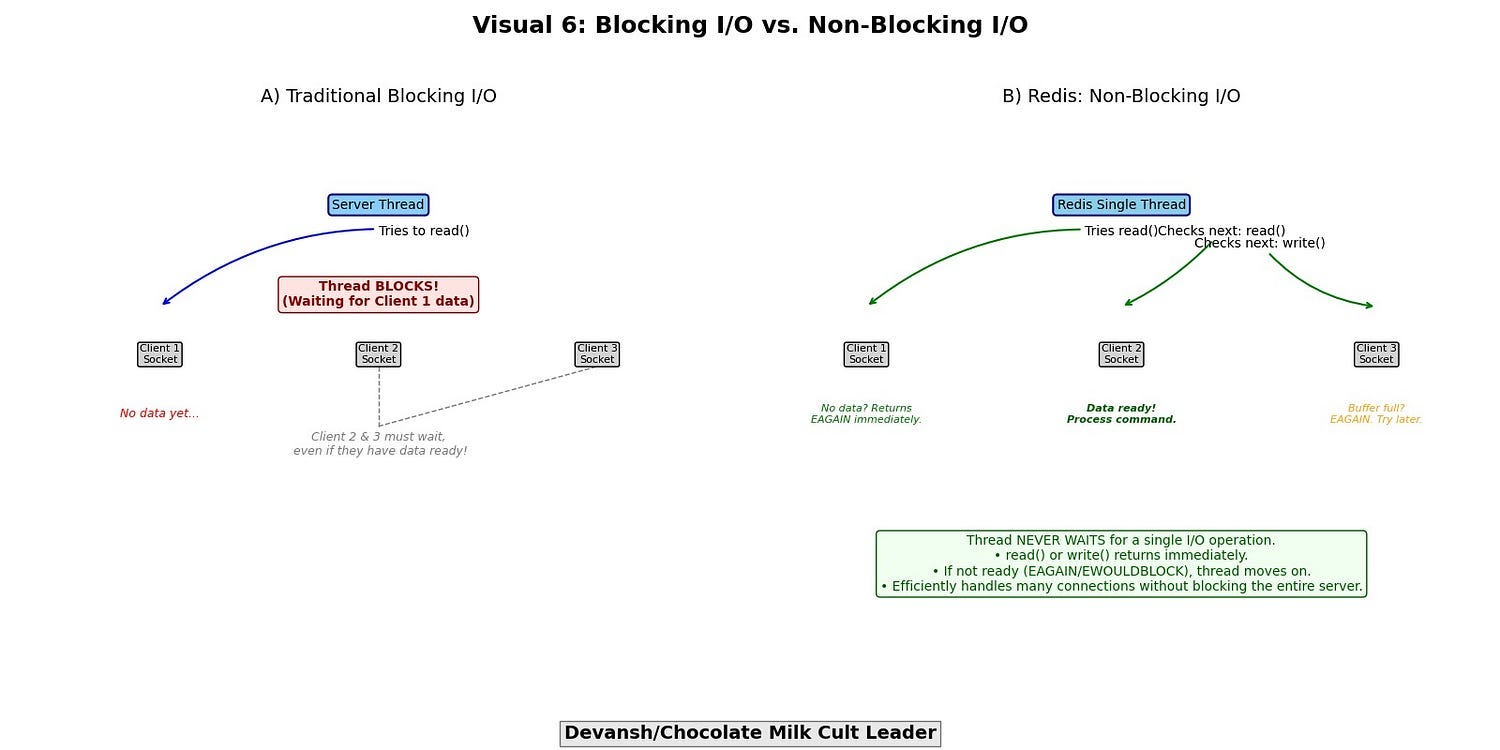
Redis exclusively uses non-blocking I/O for network communication. This means:
A read() operation on a socket will return immediately, either with available data or an indication (e.g., EAGAIN or EWOULDBLOCK) that no data is currently available.
A write() operation will write as much data as possible to the socket’s send buffer and return, indicating how much was written, or again, signal EAGAIN if the buffer is full.
The single thread never waits idly for a specific I/O operation to complete.
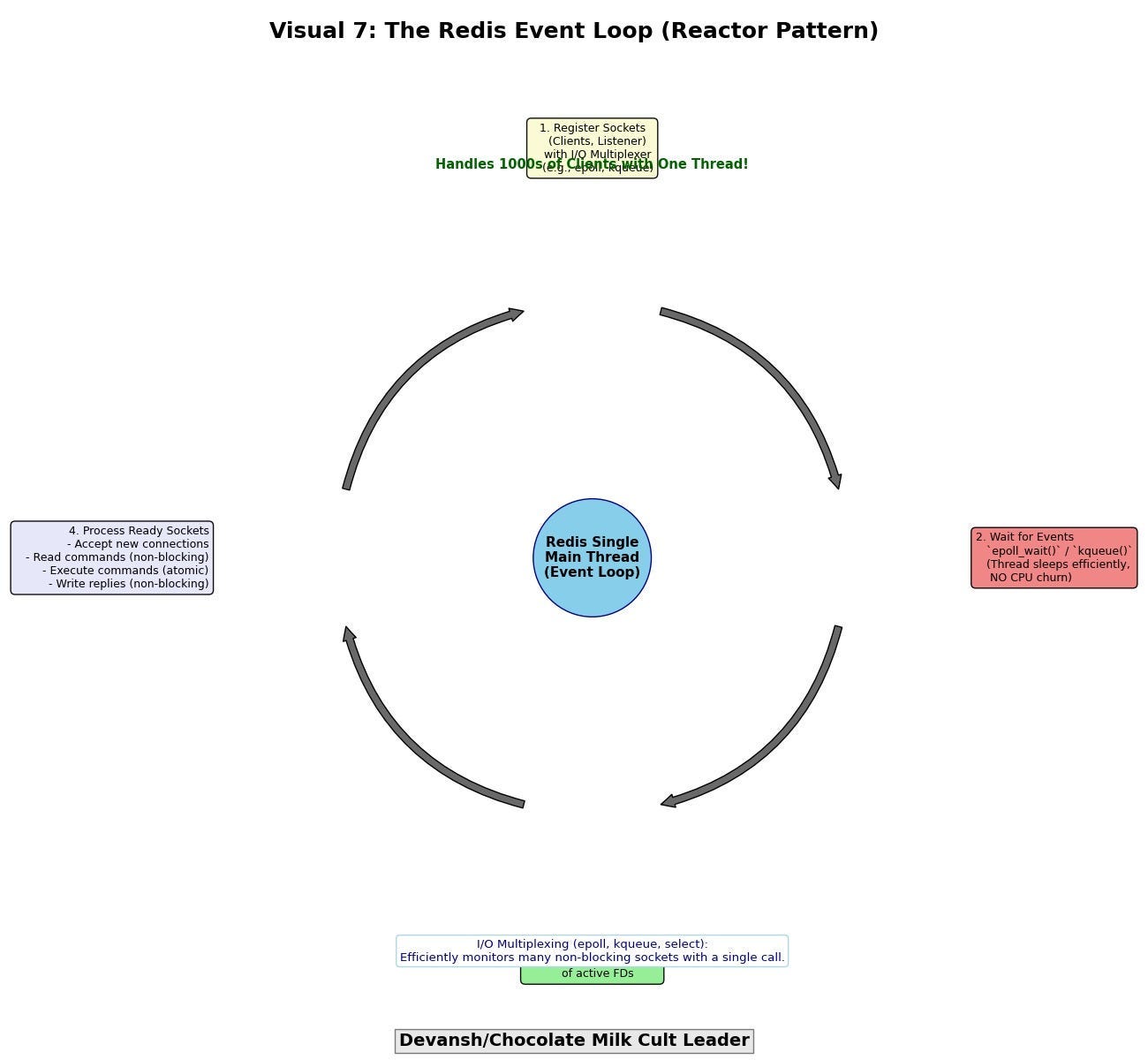
I/O multiplexing via epoll (Linux), kqueue (BSD/macOS), or select (legacy): To efficiently manage many non-blocking sockets, Redis employs system calls like epoll (Linux), kqueue (BSD/macOS), or, historically, select/poll. These mechanisms allow a single thread to monitor a large set of file descriptors (sockets) for various types of I/O events (e.g., “data available to read,” “socket ready for writing”).
The operational flow forms an event loop (often implementing the Reactor design pattern):
Registration: All active client connection sockets (and the listening socket for new connections) are registered with the I/O multiplexing facility, specifying the events of interest (e.g., readability for client sockets, acceptability for the listening socket).
Waiting for Events: The single main thread makes a single, blocking call to the I/O multiplexing primitive (e.g., epoll_wait()). This call efficiently puts the thread to sleep until one or more of the monitored sockets become “ready” for an I/O operation. Crucially, while the thread is “blocked” in this call, it consumes virtually no CPU resources.
Event Dispatching: When the epoll_wait() call returns, it provides a list of sockets that have pending events.
Processing Ready Sockets: The thread iterates only through these ready sockets.
If a listening socket is ready, it means a new client connection attempt has arrived; Redis accept()s it, sets the new socket to non-blocking, and registers it with the event loop for read events.
If a client socket is ready for reading, Redis performs a non-blocking read() to get the client’s command, parses it, executes it (this is the single-threaded, atomic command execution), and prepares the reply.
If a client socket is ready for writing (meaning its send buffer has space), Redis performs a non-blocking write() to send pending reply data. If not all data can be sent, Redis remembers the remainder and re-registers interest in writability for that socket.
Loop: The thread then returns to the epoll_wait() call, waiting for the next batch of I/O events.
Result:
Redis can juggle tens of thousands of clients on a single thread. Only active connections consume cycles. Idle ones cost nothing.
Background Threads — Strictly Out-of-Path
Redis does use threads. But they are strictly out-of-band:
Persistence: RDB snapshots and AOF rewrites run in background threads.
Memory Reclamation: Commands like
UNLINKoffload large key deletion to background freeing.Cluster Communication: In Redis Cluster mode, inter-node messaging has its own loop.
These threads never access core data structures directly. They exist to offload latency, not to parallelize access.
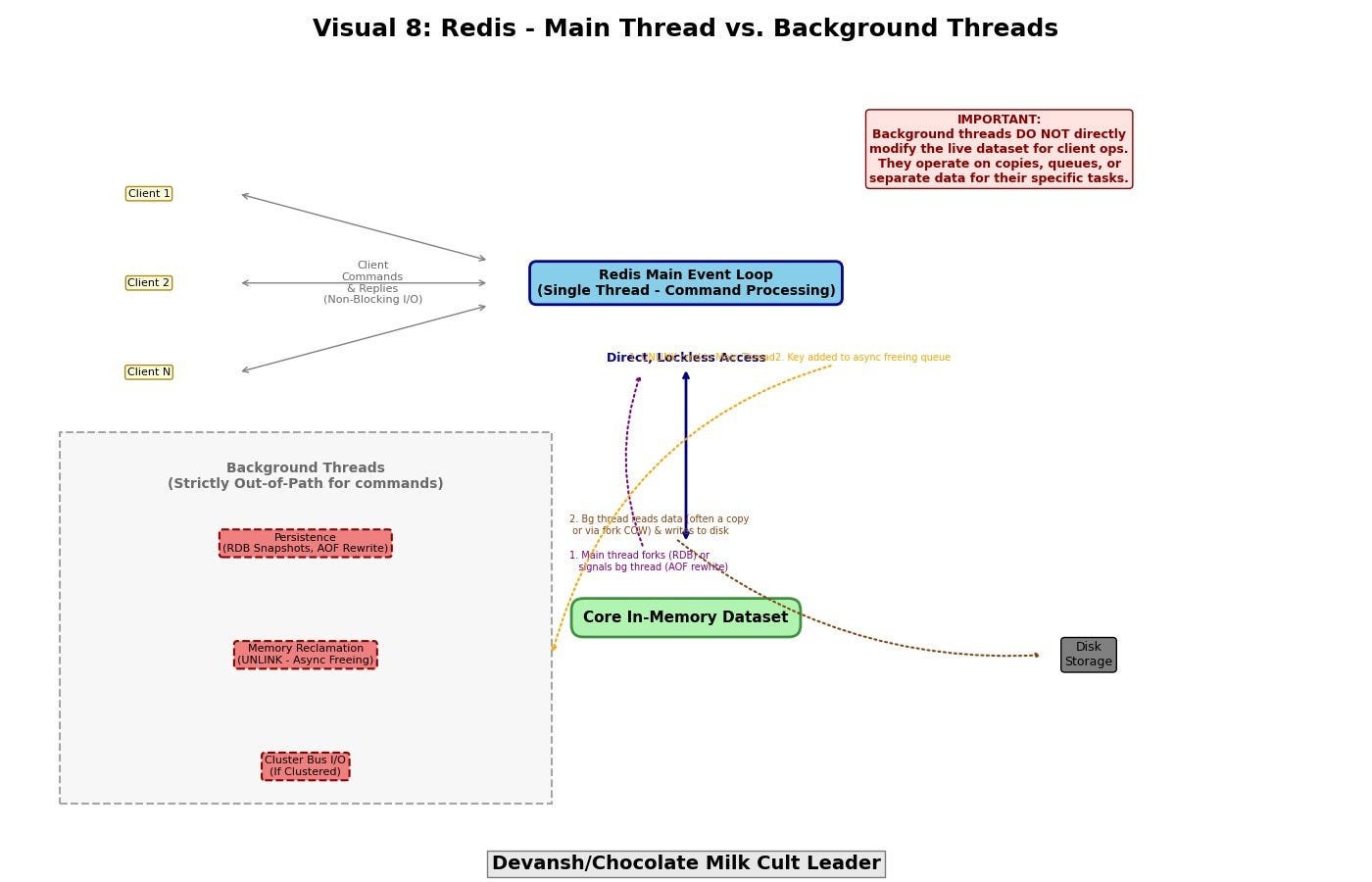
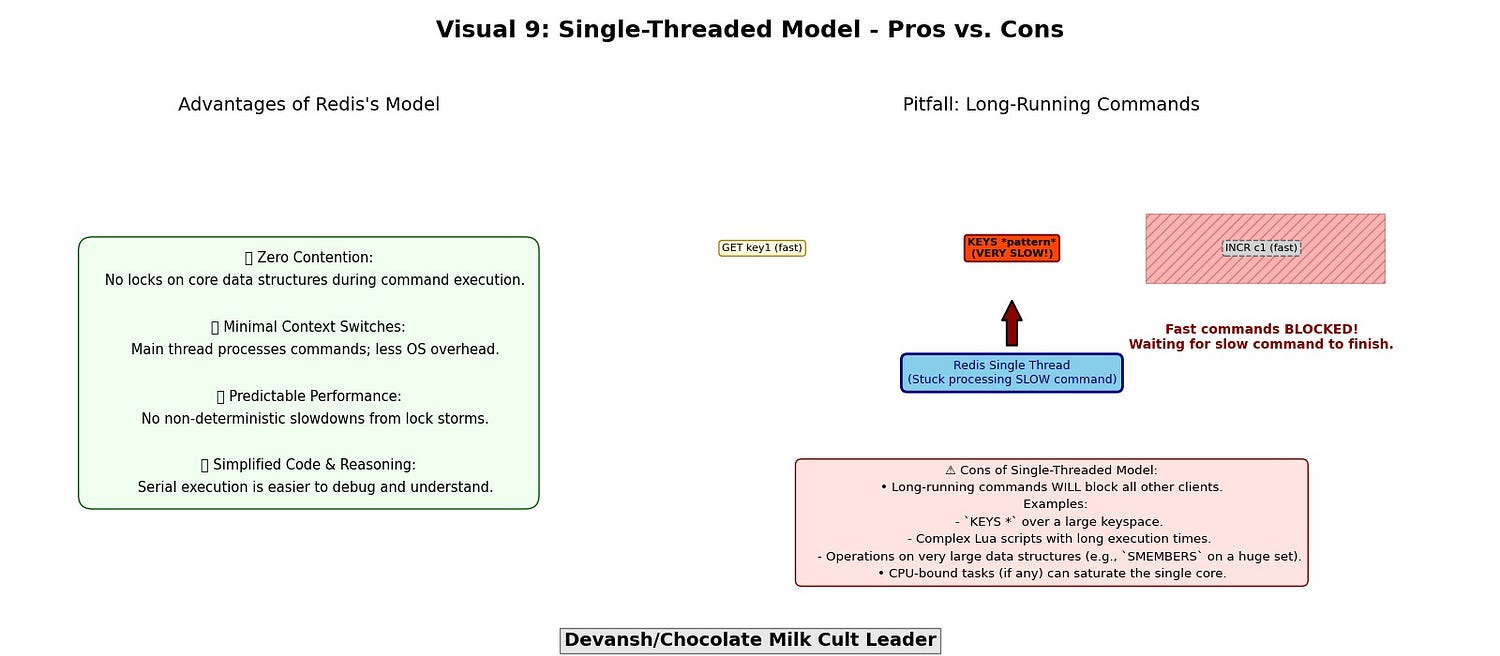
Advantages:
Zero contention: No locks, no stalls.
Minimal context switches: One thread, one context.
Predictable performance: No nondeterministic slowdowns from contention storms.
Simplified code: The event loop is finite, serial, inspectable.
Cons:
Long-running commands block everything.
Expensive Lua scripts
Commands scanning large datasets (
KEYS *,SMEMBERSon huge sets)Poorly scoped blocking ops
Redis’s strength becomes fragility if misused. That’s why command design — and dataset shaping — must respect this model.
Summary: Single-Threaded as a Weapon, Not a Weakness
Redis’s single-threaded command processor, far from being a limitation, is a masterstroke of engineering pragmatism. By combining it with a highly efficient non-blocking I/O and event-driven architecture, Redis:
Eliminates the primary source of scalability bottlenecks in traditional multi-threaded databases: lock contention on shared data.
Drastically Reduces context switching overhead within its critical processing loop.
Vastly Simplifies the core logic, leading to greater robustness and maintainability.
This design acknowledges that for its target workload — short, fast, in-memory operations — the overhead of managing multi-threaded concurrency around data access would yield a net loss in performance and a net gain in complexity. Redis chooses simplicity and raw, unimpeded execution speed for its core operations, a decision that has proven remarkably effective.
Conclusion: Redis as a Closed System of Performance Guarantees
Redis isn’t optimized — it’s bounded. Every subsystem operates under tight constraints engineered for minimal overhead. The result is not just speed, but predictable speed.
RAM removes I/O variance.
Tailored data structures compress access paths.
Single-threaded execution deletes concurrency tax.
Non-blocking I/O multiplexing aligns system time with client readiness.
Each design choice resolves a specific source of unpredictability. Nothing is redundant. Nothing is generalized.
There is no need to coordinate what never competes. No need to parallelize what never stalls. No need to abstract what will never change.
This is not minimalism. It’s total exclusion of friction — by design, not accident.
Redis is what happens when you commit to one performance profile and build everything else to serve it.
Thank you for being here, and I hope you have a wonderful day.
Find yourself someone as commited to you as Reddit is to simplicity,
Dev ❤
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).

If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
Thanks for this one. Super insightful 🌟