


Deepfake Detection: Building the Future with Advanced AI Techniques [Deepfakes]
How to Detect Deepfakes with AI Part 2: A Complete Pipeline

Hey, it’s Devansh 👋👋
This article is part of a mini-series on Deepfake Detection. We have 3 articles planned-
Proving that we can leverage artifacts in AI-generated content to classify them (here)
Proposing a complete system that can act as a foundation for this task. (here)
A discussion on Deepfakes, their risks, and how to address them (here)
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly.
PS- We follow a “pay what you can” model, which allows you to support within your means, and support my mission of providing high-quality technical education to everyone for less than the price of a cup of coffee. Check out this post for more details and to find a plan that works for you.
Executive Highlights (TL;DR of the article)
This article is part 2 of a 3-part series on Deepfake Detection (make sure you catch Part 1 for context). As a quick reminder, we hope to build a Deepfake Detection system that can classify between 3 types of inputs: real, deep-fake (we meld the face of person 1 on the photo of person 2 in a realistic way. This is the traditional technique for Deepfakes), and ai-generated (images that use AI to build from scratch, like ImageGen, DALLE etc). This is different to traditional Deepfake detections, which only work on binary classification. I believe this oversimplifies the problem and does not adequately reflect the constantly changing nature of deepfakes. That is why we have yet to see a major mainstream solution to Deepfake detection despite a lot of money and interest over the last ~6 years.
We do so by detecting artifacts that get embedded in the Deepfake Generation process, and are common across various methods. Having validated the idea in Part 1, we will now build on the foundation to discuss the next generation of Deepfake Detection. Our next-gen system will look to build on our method by integrating/refining the following components-
Data Augmentation: DA is the process of applying filters to data samples to create new ones.

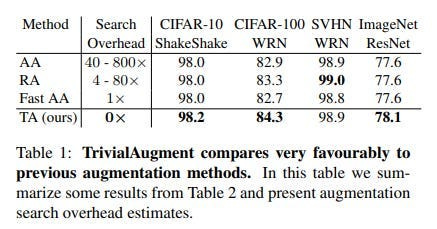
Done right, it can help with robustness, generalization, and stability at a fraction of the cost. The most impressive demonstration of this was Google, which used 12 times fewer images than its competitors (300 m to 3.5 Billion) to beat all it’s competitors on ImageNet (this is especially impressive given that none of their 300 M million images were labeled, which is not the case for the other competitors). We’ll use a policy like TrivialAugment + StyleTransfer, for it’s superior performance, cost, and benefits. We will also briefly discuss why Data Augmentation will be useful in this case.
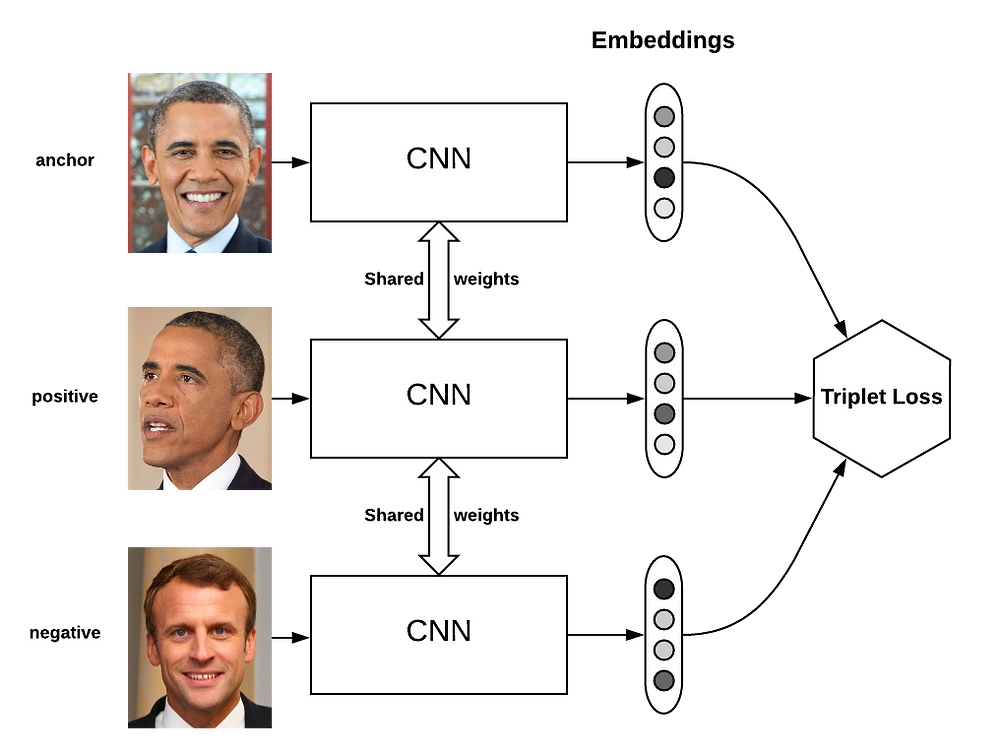
Feature Extraction- This is the most important part of our Classification system. Our performance and retraining process lives and dies by the feature extraction. To keep costs down, we will be relying on simple models. This means that most of our performance gains will come from the features we feed into the models (which is fine b/c Feature Extraction is elite). We will combine a bunch of image-processing techniques to pull out the artifacts from a single image. The core will be the FaceNet family since most of the misinformation-related Deepfakes involve human faces.
Our method uses a deep convolutional network trained to directly optimize the embedding itself, rather than an intermediate bottleneck layer as in previous deep learning approaches. To train, we use triplets of roughly aligned matching / non-matching face patches generated using a novel online triplet mining method. The benefit of our approach is much greater representational efficiency: we achieve state-of-the-art face recognition performance using only 128-bytes per face.
On the widely used Labeled Faces in the Wild (LFW) dataset, our system achieves a new record accuracy of 99.63%. On YouTube Faces DB it achieves 95.12%. Our system cuts the error rate in comparison to the best published result by 30% on both datasets.
-FaceNet: A Unified Embedding for Face Recognition and Clustering
To this, we can combine Vision Transformers (since they ‘see’ different kinds of features to CNNs) and CoshNet (since it pulls out more stable embeddings based on signal analysis) to give ourselves the MSN of Image Feature Extraction.
However, we will not stop here. Given that Deepfakes also happen over video, we will extract two additional sets of features: audio data (to detect synthetically generated audio) and features that help us detect inconsistencies between image frames. These 3 feature sets will give us a more comprehensive detection platform. We can also make this more advanced with advanced Feature Engineering, but that will left for client-specific refinements.

Models- We will use an ensemble of fairly simple models. A well-selected ensemble allows us to compensate for the weakness of one model by sampling a more diverse search space-
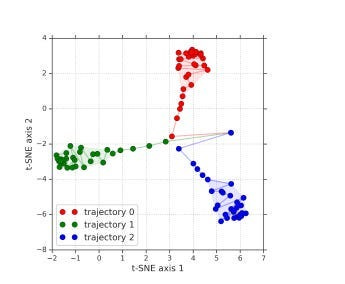
Using simple models will keep inference costs low (using a few simple models is often cheaper than a big model). This makes ensembles the closest thing to a cheat code, and is why so many modern LLMs are switching towards Mixture Of Experts style setups. To drive this point home, take a look at the image below. In it, an ensemble of Laplacian models is used to almost perfectly model a complex, multi-distributional set of points, which would be too difficult for a single model-
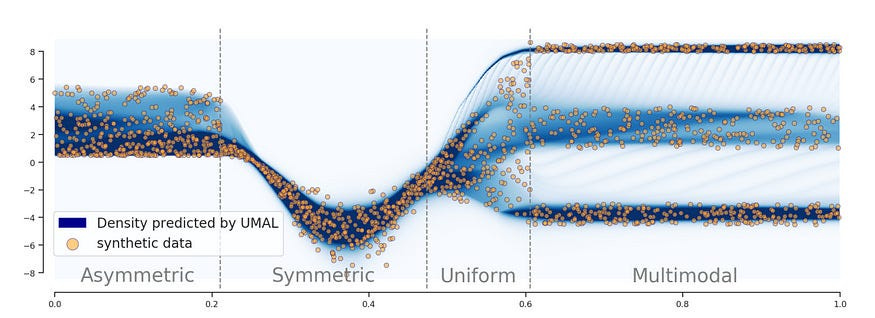
Evaluation- No need to reinvent the wheel. Simple classification metrics, with lots of cross-validation is more than enough. Applying some monitoring can help a lot with transparency into the system + visualizations of the embeddings + drift. Our variation on the Triplet Loss will already add a the requirement to the assesment.
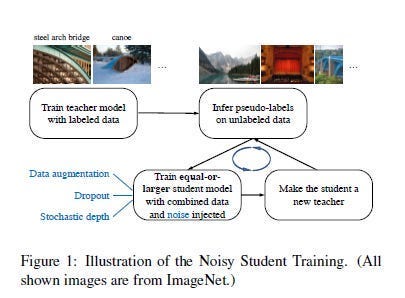
Selection/Retraining—Deepfakes will always have new generation variants. Thus, we will need a strong retraining policy that accounts for shifting trends without retraining on every sample (which would be too expensive). There are two stages to this-
Firstly, we have to talk to about selecting the right samples to train on. This is where self-supervised clustering is elite. We use self-supervised clustering to group our current dataset. Then new samples are compared against the centroids. If they are very close, we ignore them (they have no information to add) and add them to our new training if they are far away. This basic active learning style framework has shown great results in allowing models to be trained effectively while overcoming the scaling limits that hit deep-learning models.
Given how important our feature extraction is, it’s important also to put special emphasis here and catch features that are beginning to show drift. A simple but effective strategy for that is to see if you can use your current features to classify which of your features is old vs new. Split your feature data into old and new sets. Create artificial binary targets for each set. Train a supervised learning model to predict these targets. The model is essentially trying to learn the difference between the old and new data based on the features. Features that are highly important for the model to make this distinction are likely the ones that have changed significantly over time, indicating drift. This is visualized below-
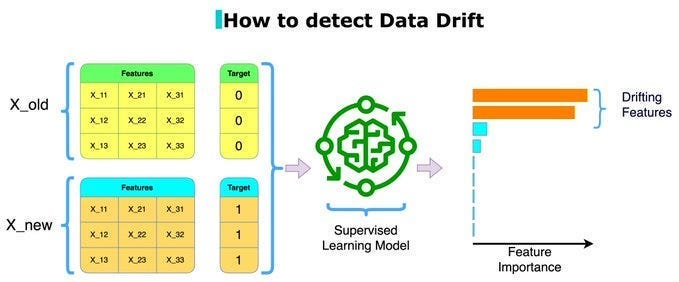
With all this covered, we now have the important foundations for our system. Let’s touch upon some of these points in more detail. Once you’re done, I’d love to hear your opinions on what you would add/remove from the system to make it better.
As always this, such a system requires constant refinement. If you want to help me solve Deepfakes, here are a few ways you can get involved-
Work with me to refine it — If your organization deals with the Deepfakes, reach out to devansh@svam.com (you can also reach out on my social media here), and we can customize the baseline solution to meet your specific needs. This way, you will have a cutting-edge detection system tailored to exactly what you need. Think about how happy that would make your investors and bosses.
Donate resources- We will publish a free, public app + website to help everyone protect themselves from Deepfakes. Naturally, this will require a lot of resources. If you have spare resources to donate- time, data, money, or computing- please reach out, and we can collaborate.
Share this- Every share puts me in front of a new audience. As someone who does not understand social media growth hacks, I rely entirely on word-of-mouth endorsements to grow our little cult and continue paying for my chocolate milk.
Build your own- You can use these lessons to build your own Detection Systems. If you do so, please share your learnings as well, so that we can all learn and grow from them. It would greatly help my goal of open-sourcing AI research to make AI reach everyone.
With that covered, let’s step into the kitchen to cook up the perfect ML-engineering pipeline for Deepfake Detection. Our first step is to talk about the ingredients, and how to pre-process them with Data Augmentation best.
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
Step 1: Data Augmentation for Deepfake Detection
As mentioned, our DA strategy will involve two pillars. Firstly, we have TrivialAugment, a strategy that randomly selects an augmentation and then applies it with a selected strength. That is it. However, it is able to match and beat more complicated strategies while requiring a fraction of the resources.
In enterprise/very high importance use-cases we can augment our DA with Neural Style Transfer for images. NST is a very cool technique, where the style of image A is grafted onto image B- giving us a new image with the style of A in the content of B.

The authors of “SinGAN-Seg: Synthetic training data generation for medical image segmentation” showed us that this can be applied effectively to enhance the quality of synthetic data and add a degree of photo-realism. This can help us eek out those few extra performance points. We can see a small but meaningful difference between naked synthetic generations and style-transferred ones.

Our use of DA will enable us to force the model to simulate the chaos of images, where input images might be impacted by angles, lighting, cropping, and other factors (one of the biggest challenges in our Deepfake system was the often titled angles and variable lighting that our testers uploaded. These factors weren’t as present in the online samples we built from). Some degree of noise works very well in helping our model not overfit to one distribution and build more robust representations, which is key in a high drift field like Deepfakes.
With our data looking nice and juicy, it’s time to start prepping it. That is where our next, and most important, step comes in.
Part 2: Robust Feature Extraction
I feel like I might have bored you with this point at this stage, but feature extraction is the highest ROI decision you can make. It can improve the quality of your preexisting data (helping your model see more with less), nudge your systems towards behaviors/relationships you value, and help with AI Security (by helping you understand what variables your model considers more or less important). As a general rule of thumb- I prefer to allocate most of my resources to data pre-processing, extractions, and performance evaluation- and relatively little on actual model training.
There are lots of cliche quotes or papers I could throw at you at this point to convince you of the importance of feature engineering. But many of you are experts and are probably bored with them. So instead, I will back up my point with this new image that Satya Nadella has allegedly asked all the Microsoft ML Engineers to pin to their body pillows as a reminder to study their data obsessively (still waiting on official confirmation from Microsoft)-

Getting back to the process, our feature engineering takes on two distinct flavors- temporal and spatial feature extractions- to reflect the complex nature of Deepfakes. Let’s cover these differences and why they matter.
Spatial Features
Most detection methods focus on Spatial Feature Recognition. This means taking an input sample at a point of time and studying it deeply. We do this in traditional image classification- where you snap a picture and run AI to analyze it. Spatial Analysis gives you all the information at a given moment. In the case of Deepfakes, we might catch artifacts such as unnatural color gradients, jarring boundary switches, differing facial features/expressions etc.
As mentioned, our core for this is the mighty FaceNet- which works very well with faces. It works by directly optimizing the embeddings (which is every efficient). I really like their triplet loss, which creates similar embeddings for the same classes and further embeddings for different classes. This contrastive style-embedding works very well b/c we’re working on classification, which has hard class labels (doing this for regressive models is possible, but much fuzzier).
On top of this, you can combine the features extracted by Vision Transformers, which objectively see differently-

And by CoshNet, which shows a remarkable ability to extract Robust Features, “CoShRem can extract stable features — edges, ridges and blobs — that are contrast invariant.”

These give you a very solid view across an image that should lead to very good performance. But what if you’re a greedy goose who wants more? That, my loves, is where we have Temporal Feature Extraction.
Temporal Feature Extraction
If you want to take things up a notch, you’re best served going for temporal feature extraction. Here, we’re analyzing the input across time- to try and catch any inconsistencies. Naturally, you will do this with Audio/Video Data.
The most obvious candidate is audio. Here, you can do basic signal processing for feature extraction (or get fancy with Deep Learning) to pick the weirdness in the audio over time that can point to synthetic generations. This is well-established, so I won’t harp on about it.
When I was researching what could be done temporally with video data, I came across — Image Pattern Classification Using MFCC and HMM- which seems to be made for this task-
“We propose a novel method for recognizing temporally or spatially varying patterns using MFCC (mel-frequency ceptral coefficient) and HMM (hidden Markov model). MFCC and HMM have been adopted as de facto standard for speech recognition. It is very useful in modeling time-domain signals with temporally varying characteristics. Most images have characteristical patterns, so HMM is expected to model them very efficiently. We suggest efficient pattern classification algorithm with MFCC and HMM, and showed its improved performance in MNISTand fashion MNIST databases.”
I’m still playing with this, but it seems promising for detecting temporal visual artifacts like:
Inconsistent lip movements in audio-visual deepfakes
Unnatural blinking patterns
Subtle color or texture inconsistencies that manifest in the frequency domain
If you’re looking to boost your Deepfake detection, play around with this and see how it does. Of course, as we build massive feature sets, it’s important to do saliency calculations and other feature engineering to run a tight ship.
I will skip the modeling and evaluation components because I don’t have much to add. Take ensemble, use Random Forests, make sure you account for variance, and you should be good (to continue our chefing metaphor, both my cooking -throw everything into a pot- and evaluation- am I still alive- are very simple). So, let’s get to the retraining component.
Step 5: Retraining
There are so many pictures on the internet. How do we know what to keep in our training set and what to ignore? That is where our retraining comes in handy.
Our first step is to take inspiration from Meta’s “Beyond neural scaling laws: beating power law scaling via data pruning” which presents the totally unexpected conclusion that it’s best to add train samples based on maximizing information gain instead of yeeting everything into a pile, “we could go from 3% to 2% error by only adding a few carefully chosen training examples, rather than collecting 10x more random ones”

Despite my snarkiness, this paper has some great insights into self-supervised clustering for Classification (bonus points because this is on Image Classification). Firstly, their method is worth paying attention to for both it’s simplicity and effectiveness- “a self-supervised pruning metric for ImageNet, we perform k-means clustering in the embedding space of an ImageNet pre-trained self-supervised model (here: SWaV [36]), and define the difficulty of each data point by the cosine distance to its nearest cluster centroid, or prototype. Thus easy (hard) examples are the most (least) prototypical. Encouragingly, in Fig. 5C, we find our self-supervised prototype metric matches or exceeds the performance of the best supervised metric, memorization, until only 70–80% of the data is kept, despite the fact that our metric does not use labels and is much simpler and cheaper to compute than many previously proposed supervised metrics”
Given that we know K beforehand, our process is much easier. Next, if you’re unhappy with the lack of labels, you can always bring Semi-Supervised Learning to create weak-labels, which has promising results in more standard Computer Vision-
Another reason this paper is worth paying attention is that it has lots of experiments done on the pruning technique and it’s outcomes. Two things that stood out to me were how comprehensively their pruning improves transfer learning-

And that data-pruning(all kinds except random) increases class imbalances-


Given how important self-supervision is for all kinds of AI, I think this paper is worth visiting every few months.
This approach should be enough for the larger trends (catching if our images are changing over time). If you want to get more microscopic, you can start focusing on individual features to see how they’re drifting. The former is like studying the feedback your dish gets to decide what dish to cook/avoid, while the latter tries to study individual ingredients/techniques to see what worked and what didn’t. Studying feature drift can be very helpful in studying the larger trends in the images/deepfakes space, but if it’s not something you care about full-time you can probably skip the extra work.
And with that we are done. All this talk about cooking reminds me that I’ve been putting off grocery shopping for the last 4 days. You’d be shocked how far you can get on a diet of Green Apples, Oranges, Sugar Free Ice Tea, Milk (both plain and chocolate), and Bacon.
And with that, we are done-zo. Shoot me a message if you want to work together on this. Otherwise, I’ll catch you later. Love you, Byeeee!! ❤
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819