
Multimodal RAG — Intuitively and Exhaustively Explained
Modern RAG for modern models.


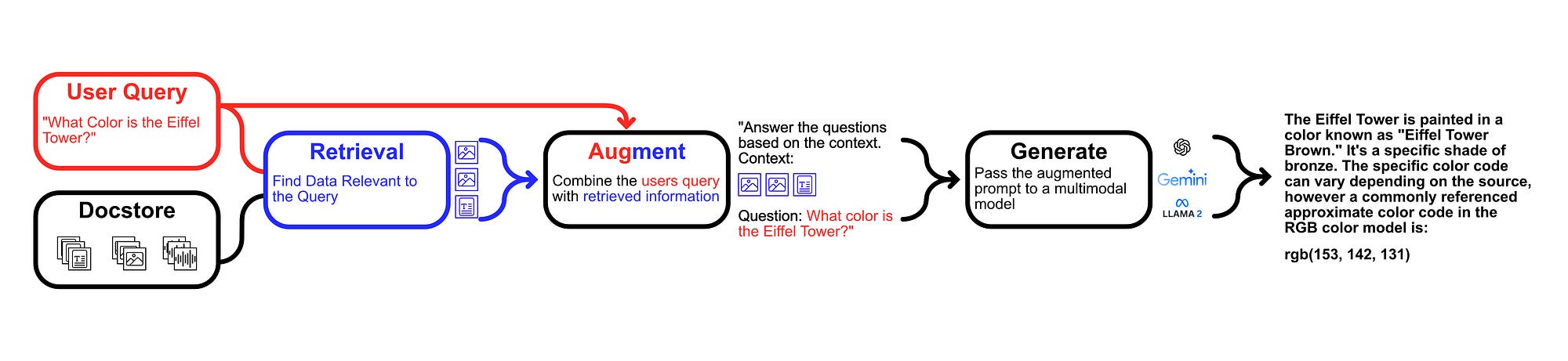
Multimodal Retrieval Augmented Generation is an emerging design paradigm that allows AI models to interface with stores of text, images, video, and more.
In exploring this topic we’ll first cover what retrieval augmented generation (RAG) is, the idea of multimodality, and how the two are being combined to make modern multimodal RAG systems. Once we understand the fundamental concepts of multimodal RAG, we’ll build a multimodal RAG system ourselves using Google Gemini and a CLIP style model for encoding.
Who is this useful for? Anyone interested in modern AI.
How advanced is this post? Even though multimodal RAG is at the forefront of AI, it’s intuitively simple and accessible. This article should be interesting to senior AI researchers, while simple enough for a beginner.
Pre-requisites: None
A Brief Introduction to Retrieval Augmented Generation
Before we get into Multimodal RAG, let’s briefly go over traditional Retrieval Augmented Generation (RAG). Basically, the idea of RAG is to find information that’s relevant to a user's query, then inject that information into a prompt and pass it to a language model.

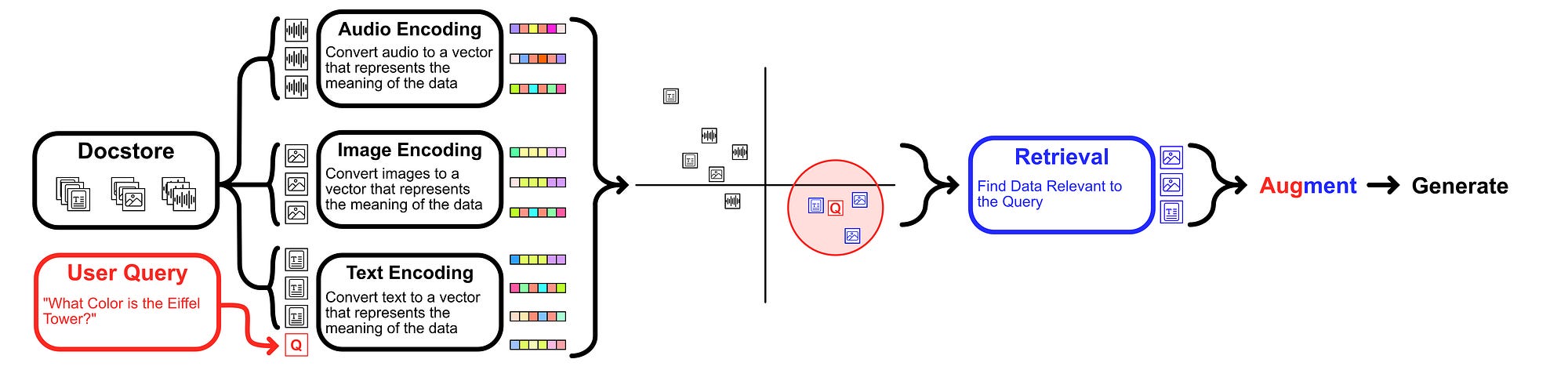
The retrieval of a RAG system is typically possible because of something called an “embedding”. Basically, to embed something, we use fancy AI models to turn information into a vector that somehow represents that information.

This process is done with a set of reference documents, as well as the users query. The distance between these vectors can be calculated, with the smallest distances between a document and the users query being deemed the most relevant.

Once a RAG system has retrieved sufficient relevant information, the users query and the relevant documents are used to construct an augmented prompt, which is passed to a language model for generation.
"Answer the customers prompt based on the following context:
==== context: {document title} ====
{document content}
...
prompt: {prompt}"This general system typically pre-supposes that the entire knowledge base is made up of text that can be passed to a language model, but many sources of knowledge contain much more than text. There might be audio, video, images, etc. This is where multimodal RAG comes in.
Before we discuss multimodal RAG, let’s briefly explore the concept of multimodality.
Multimodality
In data science a “modality” is essentially a type of data. Text, images, audio, video, tables, these can all be considered different “modalities”. For a long time, these different types of data were seen as separated from one another, requiring data scientists to create one model for doing stuff with text, another to do stuff with video, etc. In recent years this conceptualization has dissolved, and models that can understand and work with multiple modalities have become both more performant and more accessible. These models, which can understand multiple types of data, are often referred to as “multimodal models”.
The idea of multimodal models typically revolves around the idea of a “joint embedding”. Basically, joint embedding is a strategy of modeling which forces the model to learn about different types of data simultaneously. One of the landmark papers in this space was CLIP, which created a robust model capable of performing tasks relating to both images and text.

Since CLIP, various modeling strategies have been created which align images and text in some way. I cover a variety of models in this domain, but these really just scratch the surface. All over the place, new models are coming out which can deal with multiple types of data.



The evolution of both Multimodality and RAG has sparked a new trend in AI: Doing RAG in multiple modalities.
Multimodal RAG
The idea of multimodal RAG is to allow a RAG system to, somehow, inject multiple forms of information into a multimodal model. So, instead of just retrieving pieces of text based on a users prompt, a multimodal RAG system might retrieve text, images, video, and other data of differing modalities.
As it exists right now, there’s three popular approaches to achieve multimodal RAG.
Approach 1: Shared Vector Space
One approach to multimodal RAG is to use an embedding which works with multiple modalities (similar to CLIP, as previously discussed). Basically, you pass your data through a bunch of encoders that are designed to play nicely with one another, then retrieve the most similar data across all modalities to the users query.
Approach 2: Single Grounded Modality
Another approach to multimodal RAG is to convert all data modalities into a single modality, typically text.

I work at a company which employs this exact strategy within a greater product offering (we call it a “multimodal transform”). While this strategy has a theoretical risk of subtle information being lost in translation, in reality we’ve found that for many applications this achieves a very high quality result with relatively minimal complexity.
Approach 3: Separate Retrieval
The third approach is to use a collection of models designed to work with different modalities. In this context, you would do retrieval many times across different models, then combine their results.

This can be useful if you have a variety of models you want to be able to build and optimize for different modalities, or if you’re simply working with a modality which isn’t available in existing modeling solutions.
Implementing Multimodal RAG in Google Vertex
Now that we’re armed with a general understanding of multimodal RAG, let’s experiment with a simple example. We’ll do retrieval across three pieces of information:
An audio file where I say (with poor pronunciation) that my favorite harpist is Turlough O’Carolan
An image containing a picture of the Lorenz Attractor
An excerpt from the Wikipedia article for “All Quiet on The Western Front”
Using this data, we’ll construct a simplistic RAG system which can answer the question “who is my favorite harpist?”
Full code can be found here.
Setup
First let’s do some bookkeeping. We’re going to use pydub to help us out with audio:
!pip install pyduband then we can configure API keys so we can use Google Gemini.
import os
import google.generativeai as genai
from google.colab import userdata
os.environ["GOOGLE_API_KEY"] = userdata.get('GeminiAPIKey')
genai.configure(api_key=os.environ["GOOGLE_API_KEY"])Downloading the Data
I put all the files in my GitHub repo, so we can just download them from there. First we can download the image from our dataset, and also save it to the file system for later use.
import requests
from PIL import Image
from IPython.display import display
import os
# Loading image
url = 'https://github.com/DanielWarfield1/MLWritingAndResearch/blob/main/Assets/Multimodal/MMRAG/Lorenz_Ro28-200px.png?raw=true'
response = requests.get(url, stream=True)
image = Image.open(response.raw).convert('RGB')
# Save the image locally as JPG
save_path = 'image.jpg'
image.save(save_path, 'JPEG')
display(image)
Then, we can download our audio file
from pydub import AudioSegment
import numpy as np
import io
import matplotlib.pyplot as plt
import wave
import requests
# Downloading audio file
url = "https://github.com/DanielWarfield1/MLWritingAndResearch/blob/main/Assets/Multimodal/MMRAG/audio.mp3?raw=true"
response = requests.get(url)
audio_data = io.BytesIO(response.content)
# Converting to wav and loading
audio_segment = AudioSegment.from_file(audio_data, format="mp3")
# Downsampling to 16000 Hz
#(this is necessary because a future model requires it to be at 16000Hz)
sampling_rate = 16000
audio_segment = audio_segment.set_frame_rate(sampling_rate)
# Exporting the downsampled audio to a wav file in memory
wav_data = io.BytesIO()
audio_segment.export(wav_data, format="wav")
wav_data.seek(0) # Back to beginning of IO for reading
wav_file = wave.open(wav_data, 'rb')
# converting the audio data to a numpy array
frames = wav_file.readframes(-1)
audio_waveform = np.frombuffer(frames, dtype=np.int16).astype(np.float32)
# Rendering audio waveform
plt.plot(audio_waveform)
plt.title("Audio Waveform")
plt.xlabel("Sample Index")
plt.ylabel("Amplitude")
plt.show()
And, finally, our Wikipedia transcript
import requests
# URL of the text file
url = "https://github.com/DanielWarfield1/MLWritingAndResearch/blob/main/Assets/Multimodal/MMRAG/Wiki.txt?raw=true"
response = requests.get(url)
text_data = response.text
# truncating length for compatibility with an encoder that accepts a small context
# a different encoder could be used which allows for larger context lengths
text_data = text_data[:300]
print(text_data)
And, thus, we have an audio file (which contains me saying who my favorite harpist is) as well as an image and text file.
Grounding Audio in Text
It’s possible to find encoders which support audio, images, and text, but they’re a bit more esoteric than encoders which support only images and text. I’m planning on doing a comprehensive article on Google Vertex where I test the limits of some of these less common data science applications/modalities. To make our lives easier for now, though, we’ll be using a speech to text model to turn our audio into text.
import torch
from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
#the model that generates text based on speech audio
model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-medium-librispeech-asr")
#a processor that gets everything set up
processor = Speech2TextProcessor.from_pretrained("facebook/s2t-medium-librispeech-asr")
#passing through model
inputs = processor(audio_waveform, sampling_rate=sampling_rate, return_tensors="pt")
generated_ids = model.generate(inputs["input_features"], attention_mask=inputs["attention_mask"])
#turning model output into text
audio_transcription = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
audio_transcription
As you can see, the speech to text translation is less than ideal. Turlough O’Carolan was a Celtic harpist from the 1600s, and I have no idea how to pronounce his name. I tried it a few times, and thus the transcription is absolutely ridiculous.
Embedding
Now that we have our audio converted to a textual representation, we can use a CLIP style model to encode our images and text. If you’re unfamiliar with CLIP style models, they’re a type of model which understands how to represent both images and text such that similar things have similar vectors. I have a whole article on the topic:

{kind=link}
Anyway, we can use one of those to encode our images and text. First of all, let’s actually define our query:
query = 'who is my favorite harpist?'Then let’s embed everything with a CLIP style model from huggingface.
from transformers import CLIPProcessor, CLIPModel
# Load the model and processor
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# Encode the image
inputs = processor(images=image, return_tensors="pt")
image_embeddings = model.get_image_features(**inputs)
# Encode the text
inputs = processor(text=[query, audio_transcription, text_data], return_tensors="pt", padding=True)
text_embeddings = model.get_text_features(**inputs)Then, we can unpack those results to get the encoding for the text, image, audio, and query, and calculate how different the data is to the query. We’ll use cosine similarity in this context, which is essentially a measure of the angle between the two vectors. For cosine similarity, if two vectors point in the same direction their cosine similarity is high.
import torch
from torch.nn.functional import cosine_similarity
# unpacking individual embeddings
image_embedding = image_embeddings[0]
query_embedding = text_embeddings[0]
audio_embedding = text_embeddings[1]
text_embedding = text_embeddings[2]
# Calculate cosine similarity
cos_sim_query_image = cosine_similarity(query_embedding.unsqueeze(0), image_embedding.unsqueeze(0)).item()
cos_sim_query_audio = cosine_similarity(query_embedding.unsqueeze(0), audio_embedding.unsqueeze(0)).item()
cos_sim_query_text = cosine_similarity(query_embedding.unsqueeze(0), text_embedding.unsqueeze(0)).item()
# Print the results
print(f"Cosine Similarity between query and image embedding: {cos_sim_query_image:.4f}")
print(f"Cosine Similarity between query and audio embedding: {cos_sim_query_audio:.4f}")
print(f"Cosine Similarity between query and text embedding: {cos_sim_query_text:.4f}")
Here we can see that the embedding derived from the audio transcript is deemed as the most relevant.
RAG
Now that we have embeddings for each piece of data, we can do “Retrieval Augmented Generation”.
Retrieve: find the thing(s) that are the most relevant to the query.
Augment: stick those things into a prompt for the language model, along with the query.
Generate: Pass that to a language model to generate an answer.
We can do that using a few if statements in this simplified example:
# putting all the similarities in a list
similarities = [cos_sim_query_image, cos_sim_query_audio, cos_sim_query_text]
result = None
if max(similarities) == cos_sim_query_image:
#image most similar, augmenting with image
model = genai.GenerativeModel('gemini-1.5-pro')
result = model.generate_content([query, Image.open('image.jpeg')])
elif max(similarities) == cos_sim_query_audio:
#audio most similar, augmenting with audio. Here I'm using the transcript
#rather than the audio itself
model = genai.GenerativeModel('gemini-1.5-pro')
result = model.generate_content([query, 'audio transcript (may have inaccuracies): '+audio_transcription])
elif max(similarities) == cos_sim_query_text:
#text most similar, augmenting with text
model = genai.GenerativeModel('gemini-1.5-pro')
result = model.generate_content([query, text_data])
print(result.text)
Gemini really had to put your boy on blast.
Conclusion
While it’s hard to say anything for certain in this rapidly changing field, it seems like multimodal RAG might be a critical skill in the coming wave of AI productization. I think it’s fair to say that RAG as a whole, multimodal or otherwise, will continue to evolve as demands of the technology push the state of the art to new heights, and new build paradigms become approachable.
As multimodal RAG is now, we touched all the high points:
We briefly explored RAG, and Multimodality
We explored three approaches to multimodal RAG : Shared Vector Space, Single Grounded Modality, and Separate Retrieval
We then implemented a simple Multimodal RAG example ourselves, using a combination of the grounded modality and shared vector space approaches.