
Scaling Pinterest — From 0 to 10s of Billions of Page Views a Month in Two Years [System Design Sundays]
How Pinterest Scaled to 11 Million Users With Only 6 Engineers

Hey, it’s your favorite cult leader here 🐱👤
On Sundays, I will go over various Systems Design topics⚙⚙. These can be mock interviews, writeups by various organizations, or overviews of topics that you need to design better systems. 📝📝
To get access to all the articles, support my crippling chocolate milk addiction, and become a premium member of this cult, use the button below-
p.s. you can learn more about the paid plan here.
Recently I came across an excellent YouTube video, “How Pinterest Scaled to 11 Million Users With Only 6 Engineers” and the following referenced article, “Scaling Pinterest — From 0 to 10s of Billions of Page Views a Month in Two Years”. I thought they were both excellent resources to learn about System Design (would highly recommend that all of you check both out). This article will be a summary of what I found most important while studying these sources.
A Roadmap of Pinterest’s Evolution
Pinterest’s scaling journey can be divided into four distinct phases:
The Age of Finding Yourself: This phase was characterized by rapid prototyping and evolving product requirements, managed by a small engineering team.
The Age of Experimentation: Exponential user growth demanded rapid scaling, leading to the adoption of numerous technologies. However, this resulted in a complex, fragile system.

The Age of Maturity: This phase involved a conscious simplification of their architecture, focusing on mature, scalable technologies like MySQL, Memcache, and Redis. Instead of adding to the tech stack, Pinterest invested the money into growing what was working well.

The Age of Return: With the right architecture in place, Pinterest continued its growth trajectory simply by scaling horizontally, validating its choices.

Let’s why these were the technologies left standing after the brutal re-architecture purge.
Core Technologies: Building Blocks of Scalability
Pinterest prioritized technologies that were reliable, well-understood, and could easily scale with their growing user base. Let’s delve into these technologies:
MySQL: A robust and mature relational database management system known for its stability and a wide community of users. This ensured easy maintenance, troubleshooting, and hiring engineers familiar with the technology. Most importantly it is my favorite f-word: free.
Memcache: This is a simple, high-performance system for caching frequently accessed data in memory. Memcache’s simplicity and reliability made it ideal for offloading database reads. Also free.
Redis: A versatile data store capable of handling various data structures and offering flexibility in persistence and replication. This allowed Pinterest to customize the persistence strategy based on data sensitivity. As you may guess, this is also free.
Solr: Chosen b/c it can be used quickly. Also the team “Tried Elastic Search, but at their scale it had trouble with lots of tiny documents and lots of queries.”
Clustering vs Sharding: How to Scale the Database
As data volume surged, Pinterest faced a critical choice: how would it distribute its database to handle the load? Two main approaches emerged, each with its own merits and drawbacks.
Understanding Clustering
“Database clustering is the process of connecting more than one single database instance or server to your system. In most common database clusters, multiple database instances are usually managed by a single database server called the master.”

Clustering in action:
A new piece of data arrives.
The clustering algorithm determines the optimal node for this data.
Data is replicated across multiple nodes for redundancy.
If a node fails, other nodes take over, ensuring data availability.
Benefits:
Automatic Scaling: Adding new nodes automatically expands capacity.
Ease of Setup: The clustering technology manages data placement and distribution, simplifying initial setup.
Geographical Data Distribution: Clusters can be spread across different geographical locations, improving data locality and resilience to datacenter outages.
High Availability: Data replication and automatic failover ensure continuous operation even when individual nodes fail.
Load Balancing: The workload is distributed across nodes, preventing any single node from becoming overwhelmed.
Drawbacks:
Complexity: Clustering introduces complex interactions between nodes, making troubleshooting and maintenance more difficult.
Maturity: Mature clustering technologies were limited at the time Pinterest was making this decision, resulting in fewer experienced engineers and community support.
Upgrade Challenges: Upgrading a cluster can be complicated due to the need for coordinated changes across multiple nodes.
Single Point of Failure: The cluster management algorithm, responsible for coordinating activities, can become a single point of failure. Issues with this algorithm can impact the entire cluster.
Understanding Sharding
Imagine dividing your data into smaller chunks and placing each chunk on a separate, independent server. This is sharding. Instead of relying on automatic coordination, applications determine where data is located and route queries accordingly.
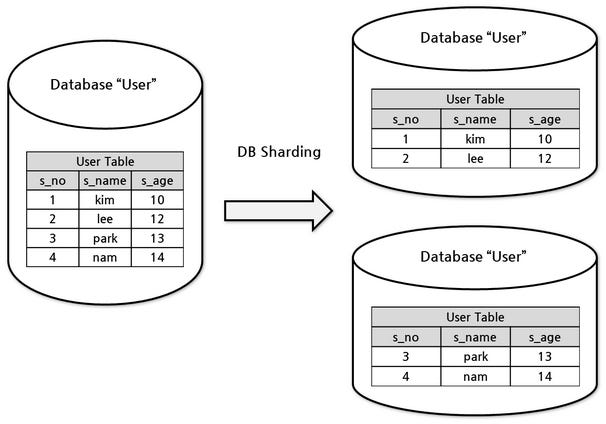
Sharding in action:
Data is partitioned based on specific criteria (e.g., user ID).
Each partition (shard) resides on a dedicated server.
Applications determine the correct shard for a given query.
Data within a shard can be replicated for high availability.
Benefits:
Simpler Architecture: Sharding eliminates the complexities of inter-node communication and automatic data distribution, resulting in a simpler system to understand and manage.
Independent Scaling: Individual shards can be scaled independently, offering more granular control over resource allocation.
Clear Data Ownership: Each shard has a well-defined responsibility for a specific subset of data, eliminating the ambiguity of ownership that can arise in clusters.
Simplified Algorithm: The logic for data placement is significantly simpler than complex cluster management algorithms, reducing the likelihood of catastrophic failures.
Drawbacks:
No Database-Level Joins: Since data is spread across multiple shards, performing joins across different shards becomes challenging. This often requires denormalizing data or performing joins within the application layer.
No Database-Level Transactions: Transactions spanning multiple shards are not possible, requiring application-level logic to maintain data consistency and integrity.
Increased Application Complexity: Applications must handle shard routing and manage data consistency across shards, adding complexity to the development process.
Schema Changes are More Involved: Modifying database schemas requires applying changes to all individual shards.
Reporting Complexity: Generating reports that span multiple shards requires retrieving data from each shard and aggregating the results manually.
Why Pinterest Chose Sharding
Pinterest chose sharding over clustering due to its relative simplicity and their negative experiences with clustering during the “Age of Experimentation.” They faced:
Cluster Management Issues: Bugs in cluster management algorithms resulted in multiple outages and were difficult to troubleshoot.
Data Rebalancing Problems: Automatic rebalancing can cause performance bottlenecks and data inconsistency issues.
Data Ownership Confusion: Instances occurred where a secondary node incorrectly assumed the primary role, leading to data loss. “In one case they bring in a new secondary. At about 80% the secondary says it’s primary and the primary goes to secondary and you’ve lost 20% of the data. Losing 20% of the data is worse than losing all of it because you don’t know what you’ve lost.”
Sharding provided a more predictable and manageable approach. They were willing to trade some database-level features like joins and transactions for increased control and simplicity at the application level.
Migrating to a Sharded Architecture
The shift to sharding wasn’t instantaneous. Pinterest adopted a phased approach, meticulously executed during a feature freeze to minimize user impact:
Eliminating Joins: All MySQL joins were removed, necessitating data denormalization and increased reliance on caching to maintain performance. Aggressive caching helped to compensate for the performance impact of lost joins and the need to query multiple shards.
ID-Based Sharding: This final phase involved sharding based on a 64-bit ID. This ID embedded the shard location, eliminating the need for separate lookup tables and simplifying data routing. “All data (pins, boards, etc) for a user is collocated on the same shard. Huge advantage. Rendering a user profile, for example, does not take multiple cross shard queries. It’s fast.”
This phased approach allowed for incremental implementation and thorough validation at each stage.
The Price of Sharding: Drawbacks and Solutions
While sharding offered a more manageable approach, it came with challenges that Pinterest had to address:
Scripting for Migration: Transferring vast amounts of data to the sharded infrastructure proved far more time-consuming than anticipated, highlighting the need for robust scripting tools and processes.
Application Logic: The lack of database-level joins and transactions required developers to implement logic for maintaining data consistency and integrity within the application layer.
Schema Modifications: Altering the database schema required careful planning and application of changes across all shards.
Reporting Hurdles: Generating reports across multiple shards required additional steps to aggregate results from each shard.
Wisdom Gained: Key Takeaways from Pinterest’s Journey
Pinterest’s scaling journey offers valuable lessons for anyone architecting systems for growth:
Simplicity is Key: Choosing straightforward, well-understood technologies simplifies troubleshooting and reduces the risk of unforeseen problems.
Prioritize Scalability: Be willing to sacrifice some database features for scalability, especially in rapidly growing environments.
Design for Horizontal Growth: Choose an architecture that allows you to add more resources as your user base expands.
By embracing simplicity, emphasizing scalability, and learning from their experiences, Pinterest successfully navigated the challenges of explosive growth. Their story serves as a valuable case study for building and scaling high-performance, distributed systems.
Ready to simplify your tech journey? Subscribe to Technology Made Simple and get clear, actionable insights to boost your tech skills and career. Forget wasting time on endless tutorials — find everything you need in one place.
Special Offer: Save 20% on your first year! Here’s what you get:
Monthly Plan: 640 INR (8 USD) [Originally 800 INR]
Yearly Plan: 6400 INR (80 USD) [Originally 8000 INR]

Still hesitant? Try risk-free with our 6-month money-back guarantee. If you’re not satisfied, get a full refund, no questions asked! All you have to do is message me.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
Another consideration - a clustered approach scales data and traffic homogeneously. Sharding is more likely to result in nodes that are unused or disproportionately hot. Or, at least, heterogeneous utilization is more random in the case of clustering, more deterministic of developer decisions in the case of sharding.
The recourse, then, for high loads, is different. Clusters can be rebalanced. Shards, for read-only data, can be scaled with a second cache layer, but to scale writes would require a shard splitting procedure (which I guess is also rebalancing but you have to do it yourself).
Now, if you were to implement the routing part in a third middle layer between app & DB... Is it clustered or sharded? Both! Neither? This idea demonstrates that the distinction is ultimately a difference between which process contains the node-selection implementation. The various partitioning strategies, like DHT or lookups or ranges, can arguably be implemented in either case.
Naturally, then, sharding gives the application more explicit control, and has more scaling potential. You can squeeze more, but you need to do that squeezing, and getting it wrong can backfire. From that, I'd conjecture that a clustered system is a better fit for prototypes or chaotic access patterns or complex (heterogeneously deep or wide) data models. Sharding is a better fit for well-understood access patterns that are implicated in the data structure. Pinterest certainly fits the latter category.
If you're really crazy, you can shard clusters ( O(1) + O(log N) ), but I imagine there are few real-life scenarios where the ROI justifies that level of implementation complexity.