
[Solution]Problem 47:File Syncing Code [Google]]
A bit of a curveball, but a question you should know

To learn more about the newsletter, check our detailed About Page + FAQs
To help me understand you better, please fill out this anonymous, 2-min survey. If you liked this post, make sure you hit the heart icon in this email.
I hope y’all had fun with this question yesterday,
It’s not your typical Leetcode-style question, but it can be very helpful to mix things up. This type of question will really work on your algorithm development skills. I like such questions because they test your problem-solving ability over your ability to memorize 300+ Leetcode questions (seems like there are a lot of LinkedIn gurus teaching that recently).
Problem
This problem was asked by Google.
Implement a file syncing algorithm for two computers over a low-bandwidth network. What if we know the files in the two computers are mostly the same?
[FREE SUBS]To buy the solution for this problem, use any of the following links. The price is 3 USD. Once you send the payment, message me on IG, LinkedIn, Twitter, or by Email:
Venmo: https:/ount.venmo.com/u/FNU-Devansh
Paypal: paypal.me/ISeeThings
Or you can sign up for a Free Trial Below. Since the reception has been great, I got a special offer for y’all. You can get this newsletter free for 2 months, just by using the button below-
Step 0: Understanding the Problem Domain
Before we get into designing algorithms, it is always prudent to look at what the problem domain is. When would such an algorithm be useful/needed? Let’s take an example.
Consider video games. Every time a new patch/update drops, you want your game to be updated. If you had to reinstall all the game files for updates, things would be very slow and costly. And you’d spend a lot of time setting up the game to your liking again. No one is happy about this (except for Internet Service providers, who get to charge you more money).

To make things more efficient, what the servers do is that they go through your game files and compare them to the updated files on their servers. They only update the parts that are different. So far so good.
This should give you a clear understanding of where to go next. How can we efficiently compare the differences in the two files? Clearly, just sending the master files over the network will not be smart. What can we do to minimize the data transferred across the network?
Step 1: Computing Differences
Really this is the first major problem that we must solve to create our solution. How can we compute the differences between two text files? To answer this, first let’s define a fundamental problem, what even is a difference?
Let’s look at files in the first place. We can say that two files are separated from each other by a finite number of insertions and deletions. If we can delete some content from file A, and then add some other content to it, then we can get to be identical to file B. Nothing too strange there, but take a second to confirm it for yourself.

We are also helped by the question because it tells us that the files are mostly similar. For simplicities sake, let’s assume we want to update file B to match file A. This means that we want to implement the following program that does the following-
Look through the files and find the parts where our files differ.
Purge the parts that are different in file B.
Send the new parts of file A and add those to file B at the relevant locations.
Keep in mind the differences in content might be at the beginning, middle, or end. Our algorithm for spotting the differences should be able to accommodate them all. This is where we start doing the next part. You will see such an approach used in a lot of areas so make sure you pay special attention.
Step 3: Leveraging Checksums
The first thing we should do is break our file into chunks of a fixed size (the last chunk may be smaller than this size). Once we have our text broken up into chunks, we can get really funky.
Now we can send these chunks of text across the server, but it doesn’t help us much. Instead what we will do is run a checksum function to generate a checksum. A checksum is similar to a hash function but is intended to verify the integrity of your data rather than to index an input. The process works almost identically.
Seems like we’re getting somewhere. We chunkify file B, and checksum every individual chunk. We send this chunk through our server to compare to file A (we have also chunked A and generated the checksums here). If it’s not the same, then we know that we know this is potentially an area of purging. If our checksum doesn’t meet any matches, then the corresponding chunk of text should be added to A.
To make this process smoother, we might as well check all the checksums from B from one chunk before moving on. This way we only traverse the file once.
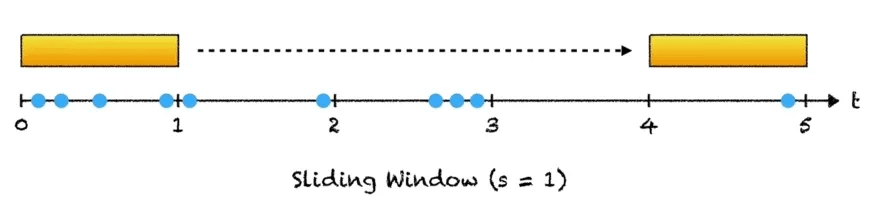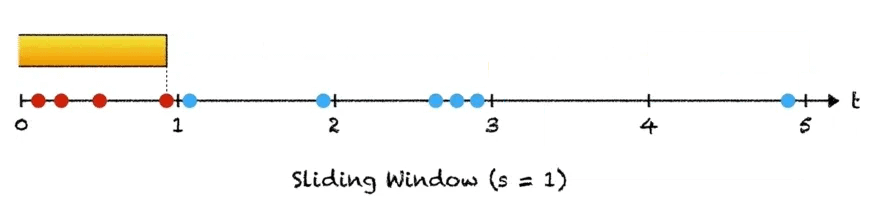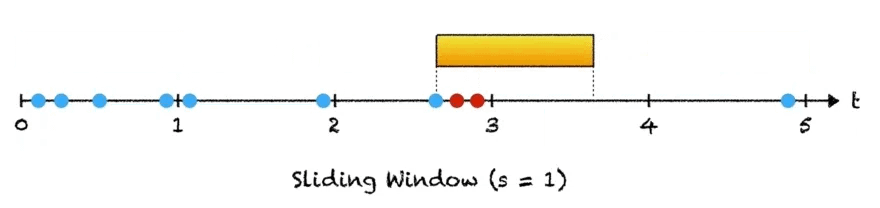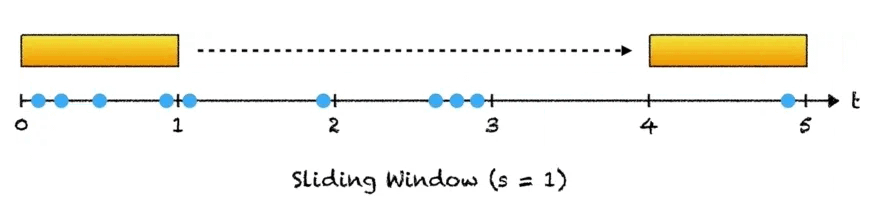
There is one thing that should stand out to you. Such a procedure would work best with a rolling checksum computation. This way we can proceed through the chunks byte by byte (when there is no match), allowing us to check for similarity at every possible offset/combination. When there is a match in chunks, we can simply move on to the next chunk.
This is where another design concern might rear its head. Computing good checksums can be very expensive. If you have large files, then you will run a lot of resources. Intuitively, we don’t even want to run our costly checksum comparison in cases where our strings are very different. But using a bad checksum will not have much benefit. So what do we do?
Step 4: Using 2 Checksums
Feels kinda like cheating doesn’t it?
Here’s what we’re going to do. When sliding our window across file A, we will use the cheap rolling checksum to test for matches. Only if there’s a match, will we use a fancier algorithm. If there is another match, then we know that the chunk exists in B.
In this case, we send a signal to B to let the file know that this file is a match. Otherwise, it sends the first byte in its block, then moves forward one byte, and repeats the process.
B receives this stream of bytes and block references and uses that to reconstruct the final version of the file on its side. Notice how this process is very efficient.
Clearly, this process requires picking very good checksums. Let’s talk about that next.
Step 5: More on Checksums
Our primary checksum will be following a sliding window approach. Thus we would want something, that is really efficient at calculating successive checksums in a rolling window. This means that if we have the checksum of a[1:5] then a[2:6] should be easy. The famous rsync algorithm, on which this question is based, uses recurrence relations (covered here) for this reason.
The second fancier algorithm should be stronger and have less error. Since this would not run very often, the cost is not as big a concern. We want to maximize performance.
And with this, your solution is good to go. Follow this process and you will ace this question in your interview
Stay Woke. I’ll see you living the dream.
Go kill all,
Devansh <3
Reach out to me on:
Instagram: https://www.instagram.com/iseethings404/
Message me on Twitter: https://twitter.com/Machine01776819
My LinkedIn: https://www.linkedin.com/in/devansh-devansh-516004168/
My content:
Read my articles: https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Get a free stock on Robinhood. No risk to you, so not using the link is losing free money: https://join.robinhood.com/fnud75