
[Solution]Problem 44: Longest Substring Without Repeating Characters (Meta / Facebook)
Two Pointers, Arrays, Hashmaps, Duplicate checking

Hello all,
Apologies for missing the solution yesterday. I had to go pick up my grandparents from the airport. That ended up being a 5.5-hour affair, because of the rains, floods, and delays. Hopefully, this amazing solution makes up for it. I’ll release the Finance Friday later today.
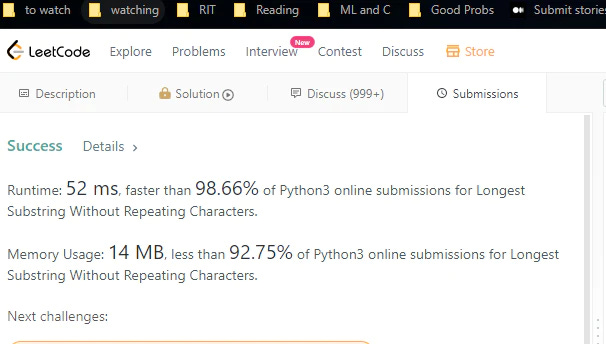
Problem
Given a string s, find the length of the longest substring without repeating characters.
Example 1:
Input: s = "abcabcbb"
Output: 3
Explanation: The answer is "abc", with the length of 3.
Example 2:
Input: s = "bbbbb"
Output: 1
Explanation: The answer is "b", with the length of 1.
Example 3:
Input: s = "pwwkew"
Output: 3
Explanation: The answer is "wke", with the length of 3.
Notice that the answer must be a substring, "pwke" is a subsequence and not a substring.You can test your solution here
[FREE SUBS]To buy the solution for this problem, use any of the following links. The price is 3 USD. Once you send the payment, message me on IG, LinkedIn, Twitter, or by Email:
Venmo: https://account.venmo.com/u/FNU-Devansh
Paypal: paypal.me/ISeeThings
Or you can sign up for a Free Trial Below. Since it’s my brother’s birthday today, I got a special offer for y’all. You can get this newsletter free for 2 months, just by using the button below-
Step 1: Setting up the question requirements
The question is a relatively straightforward one. It’s not easy to solve, but understanding what the inputs and correct outputs will look like and how they will behave is simple. This might seem like a good thing, but it can also present a very unique challenge. Since everything seems clear, it can be hard to know where to go next. It’s similar to how it’s hard to go rock-climbing on a completely smooth surface. We need footholds and rough edges.

In such a case, I like to approach the problem by rereading the problem and identifying any possible hints in the wording. For example, this question tells us that we need to keep track of letters that we have seen to check for duplicates. That immediately reminds me of using either a hashmap/dict or set (to learn more about hashing read this).

You can use other techniques like marking a spot as visited (like we do here) but that is more advanced. And may not always work. In your interviews you want to go simplest first and then build up from there. Don’t be a hero and try fancier techniques directly. The risk to reward is not worth it.
This brings up an obvious next question. Can we figure out what we want b/w a set and a dict? And how will we use them in our algorithm. We finally have a foothold to explore.
Step 2: Picking b/w a dictionary and a set
Both DS are very good when we want to insert, delete and lookup a lot of values in our solution. Sets are great when the value is all we care about. If the solution involves just checking if we have seen a value before, then a set uses less memory (since it doesn’t have a key-value pair). This is why DFS/BFS use a visited set to track if nodes have been visited.
Hashmaps or dictionaries are amazing when we want to track an associated property of the value. For example, in a graph we want to track both the node and it’s neighbors. This makes dicts the natural choice.
For this question, which of these seems to be the case. If you’re not too experienced with it, it might not be immediately obvious. That’s fine. You just need to throw the kitchen sink at the solution, and see what works. I’ve been doing Brazilian Jiu-Jitsu for a year now, and that’s still how I approach my rolls :p. So it works.
Is there anything in particular that we can catch before we start spamming all the tips and tricks you’ve picked up through our amazing relationship? Let’s look back at the problem. It’s asking us to compute the length of a substring (the details are unimportant). What do we need to compute to compute this length? Well for a substring, you need the start and end points of the string. That sounds like another foothold. If we figure out the correct starting and end points, then we will effectively figure out the length easily. Let’s figure out our algorithm for catching the two end points of our end points.

Step 3: Figuring out the start and end
We now have a clear path forward. We will build up our start and end. Since we want to avoid duplication, we will use our dictionary/set accordingly. The end results is the maximum value of end-start. Even if the details are still slightly fuzzy, atleast the solution is starting to take shape. With a final push, we should be done (or pretty close).
Let’s first understand the basic structure of our solution. Our solution will start by sliding a window through the string one step at a time. What happens when we encounter a new character? Two possible things. If we haven’t seen this character yet, we want to add this to our current sliding window. This is straightforward.
In case we have already seen the character, we have to make a few considerations. This is where splitting our problem into different cases can be a game-changer.
If our current character was not present in our current window (it was in a previous window), then we can keep adding to our index.
If our character is part of our current window, then the first thing we want to do is check if our current window is the longest yet. Next, we want to move our window forward till we don’t have any current repeating characters in our current window. Since we are going char by char, we won’t have more than 1 repeating character in our window.
As I was writing this, I had a strong sense of deja-vu. I looked through the archives. Turns out this Google question is almost identical to one we’re doing right now. This is a clear example of why you should master certain high ROI topics/techniques. They show up repeatedly. Make sure you read through that as well.

Now we get back to the question we were left with earlier- dicts or sets? We can technically use either. However, one thing that stands out to me is that we want to keep in mind the last seen index of the chars we come across. This helps us determine if we have seen the repeating char as part of our current window.
We can use sets and just check for duplicates. However, it is more efficient to track all the last seen indices of chars. This is suited for dicts/maps. However, they will take slightly more memory. Make sure you explore this tradeoff in the interview. For additional practice, try solving this problem with sets as well.
Time to wrap this question up. Let’s go into the code.
Step 4: Coding It Up
We have the pieces together. We will go through our string, letter by letter. If we haven’t seen it, we will add it to our sliding window (increasing the length of the window). If we do come across a char seen before, we will first check if that is part of our current window. How do we do that?
last_seen[letter] >= search_start If the last seen index is after the start of our sliding window, we know that the duplicating character is within the current window. Otherwise, we don’t need to worry.
Once we have this, everything else falls into place.
def lengthOfLongestSubstring(self, s: str) -> int:
last_seen = {} #last seen index
search_start = 0
longest = 0
for i in range(len(s)):
letter = s[i]
# letter not found and this letter is part of current window
if letter in last_seen and last_seen[letter] >= search_start:
length = i - search_start
longest = max(length, longest)
# we want to start our window AFTER the first occurence of the duplicate char
search_start = last_seen[letter] + 1
last_seen[letter] = i #new last seen
# calculate length: len(str) - search start
length = len(s) - search_start
# longest = max(length, longest)
longest = max(length, longest)
return longestOne final thing to notice is the last 2 lines before the return statement. Leetcode said that the output for the string “ “ is 1 (we count empty space as a char). In your interviews, make sure you ask your interviewer about such cases (“ “, empty strings, numbers/special chars). This is good practice and will give you lots of brownie points.
Time Complexity- O(N)
Space Complexity- O(1)
Make sure you share your thoughts on this question/solution/any interesting questions/developments in the comments or through my links.
Stay Woke. I’ll see you living the dream.
Go kill all,
Devansh <3
Reach out to me on:
Instagram: https://www.instagram.com/iseethings404/
Message me on Twitter: https://twitter.com/Machine01776819
My LinkedIn: https://www.linkedin.com/in/devansh-devansh-516004168/
My content:
Read my articles: https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Get a free stock on Robinhood. No risk to you, so not using the link is losing free money: https://join.robinhood.com/fnud75