
Strategies for Replication in Distributed Databases [System Design Sundays]
And the different strategies you can apply to

If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here.
To learn more about the newsletter, check our detailed About Page + FAQs
To help me understand you better, please fill out this anonymous, 2-min survey. If you liked this post, make sure you hit the heart icon in this email.
Recommend this publication to Substack over here
Take the next step by subscribing here
I have some exciting news for y’all. I’ve created a second Substack publication, called AI Made Simple. It will be dedicated to in-depth analysis of AI and Machine Learning concepts/papers. The newsletter will be completely free (there will be an option to tip if you feel like it, but no paywalled content). The content will be more sporadic. To those of you interested in Data Science/Machine Learning, use that newsletter as a supplement. You will all be added as subs there, so you don’t have to do anything. If you’d like to see the kind of content that will be uploaded, check out the most recent post.

Now let’s get back to the main idea. Let’s talk about replication in distributed databases, all the amazing benefits it brings, and how you can handle it-
Key Highlights
What is Replication- Replication is where you keep a copy of your data on multiple different machines. These machines are connected via a network, so they’re all accessible to your backend server(s). Thus instead of a centralized DB, you are now using a distributed database, spread over multiple machines.
Benefits of replication on distributed systems- Replication has the following major benefits-
Reduce latency -Take a global app like YouTube. You want Indian YT users querying a machine close to them. Same for a Brazilian user. Thus having 2 different DBs makes sense. This is similar to why you would use a Content Delivery Network (CDN), a new trend that we covered here.
Increase Availability+Security- Having data present on multiple machines means that if one DB gets corrupted/goes down, others can be used w/o any issues. This helps both Availability (which we covered this Monday) and Security (for authentication).
Increase Read Throughput - Many systems are extremely read-heavy (way more reads than writes). Take Substack for example. There are more readers on the platform than writers. Thus there are many more read operations. than write operations. Having multiple DBs can help spread the load of multiple reads across multiple machines, increasing read throughput.
Handling changes to replicated data- When you get a write request that modifies your database, how do you make sure that all the replicas reflect this write request? How do you stop replicas that haven’t updated from responding with stale data to read requests? You have 3 popular options-
Single Leader Architecture: In this architecture, one server accepts client writes and replicas pull data from it. This is the most popular and traditional way. It’s the synchronous technique, but it’s also quite rigid.
Multi Leader Architecture: In this architecture, multiple servers can accept writes and serve as a model for replicas. To avoid delay, copies should be spread out and leaders should be near all of them.
No Leader Architecture: Every server in this architecture can receive writes and function as a replica model. While it provides maximum flexibility, it makes synchronization difficult.
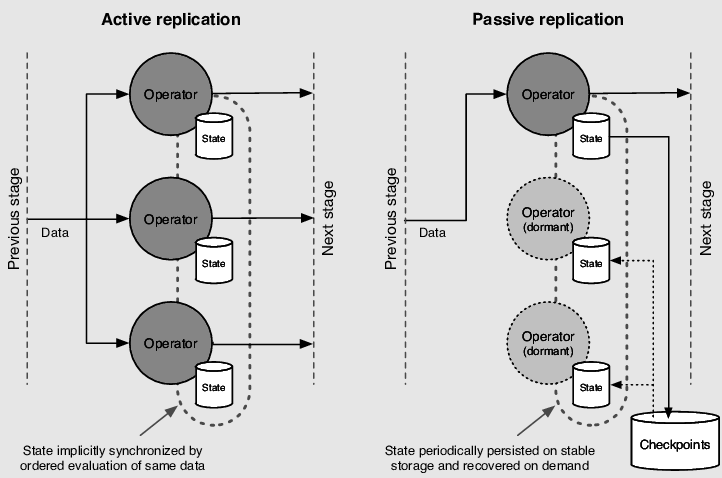
Active vs Passive Replication- Another way of viewing the data replication challenge is to differentiate b/w active and passive replication. In active replication, all replicas receive and process the same set of client requests. This ensures consistency but adds a lot of overhead to your system. In contrast to this, in passive replication, all client requests are handled by a primary server. Other replicas then adjust to the primary. This requires lesser resources, but you need to make sure to constantly check for the health of the primary server.
{kind=link}
Almost all distributed databases use one of the three approaches and they all have their pros and cons. We will do a more in-depth look into these soon. In the meanwhile, if you want to learn more check out the following resources. Much of the research for this write-up was inspired by the amazing publication Quastor. I have been recommending their publication for some time now. You can read their work here. I also referred to Data Replication in Distributed Systems: The Best Guide 101, an amazing article you can find here.

I created Technology Made Simple using new techniques discovered through tutoring multiple people in top tech firms. The newsletter is designed to help you succeed, saving you from hours wasted on mediocre resources or on the Leetcode grind. Easily find your needs met in one place. I have a 100% satisfaction policy, so you can try it out at no risk to you. Use the button below to get 20% off for up to a whole year. Using this discount will drop the prices-
800 INR (10 USD) → 533 INR (8 USD) per Month
8000 INR (100 USD) → 6400INR (80 USD) per year
In the comments below, share what topic you want to focus on. I’d be interested in learning and will cover them. To learn more about the newsletter, check our detailed About Page + FAQs
If you liked this post, make sure you fill out this survey. It’s anonymous and will take 2 minutes of your time. It will help me understand you better, allowing for better content.
https://forms.gle/XfTXSjnC8W2wR9qT9
If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here.
Stay Woke,
Go kill all,
Devansh <3
Reach out to me on:
Instagram: https://www.instagram.com/iseethings404/
Message me on Twitter: https://twitter.com/Machine01776819
My LinkedIn: https://www.linkedin.com/in/devansh-devansh-516004168/
My content:
Read my articles: https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd