
Understanding Space Based Architecture for efficient Data Processing[System Design Sundays]
A possible game-changer for edge AI, real supply chain analysis, and more

Hey, it’s your favorite cult leader here 🐱👤
On Sundays, I will go over various Systems Design topics⚙⚙. These can be mock interviews, writeups by various organizations, or overviews of topics that you need to design better systems. 📝📝
To get access to all the articles, support my crippling chocolate milk addiction, and become a premium member of this cult, use the button below-
p.s. you can learn more about the paid plan here.
Recently, I spoke to a reader of AI Made Simple (who wished to remain anonymous) while doing some market research for designing scalable AI applications in the finance industry. They asked me to look into Space Based Architecture (SBA) for data processing and pipelining. SBA seems to be gaining some attention recently, and some of its core ideas are very interesting to me. I have two main motivations for writing this post-
To introduce y’all to this idea that might potentially be big in the coming times.
To get your thoughts/experience with this/similar patterns to get a deeper understanding of the pros and cons of this system (right now, my understanding is limited mostly to what I’ve read).
The systems that supply this data must offer reliable, secure data processing and analysis, in near real-time. This is particularly important in mission-critical industries such as finance, healthcare, and ecommerce, where real-time data processing can make a significant difference in the success of the health of the business – or the patient. Space-Based Data Hubs also enable the creation of real-time applications that can react quickly to changing data.
Hope you’re ready to have some fun with this-
Key Highlights
What is Space-Based Architecture?
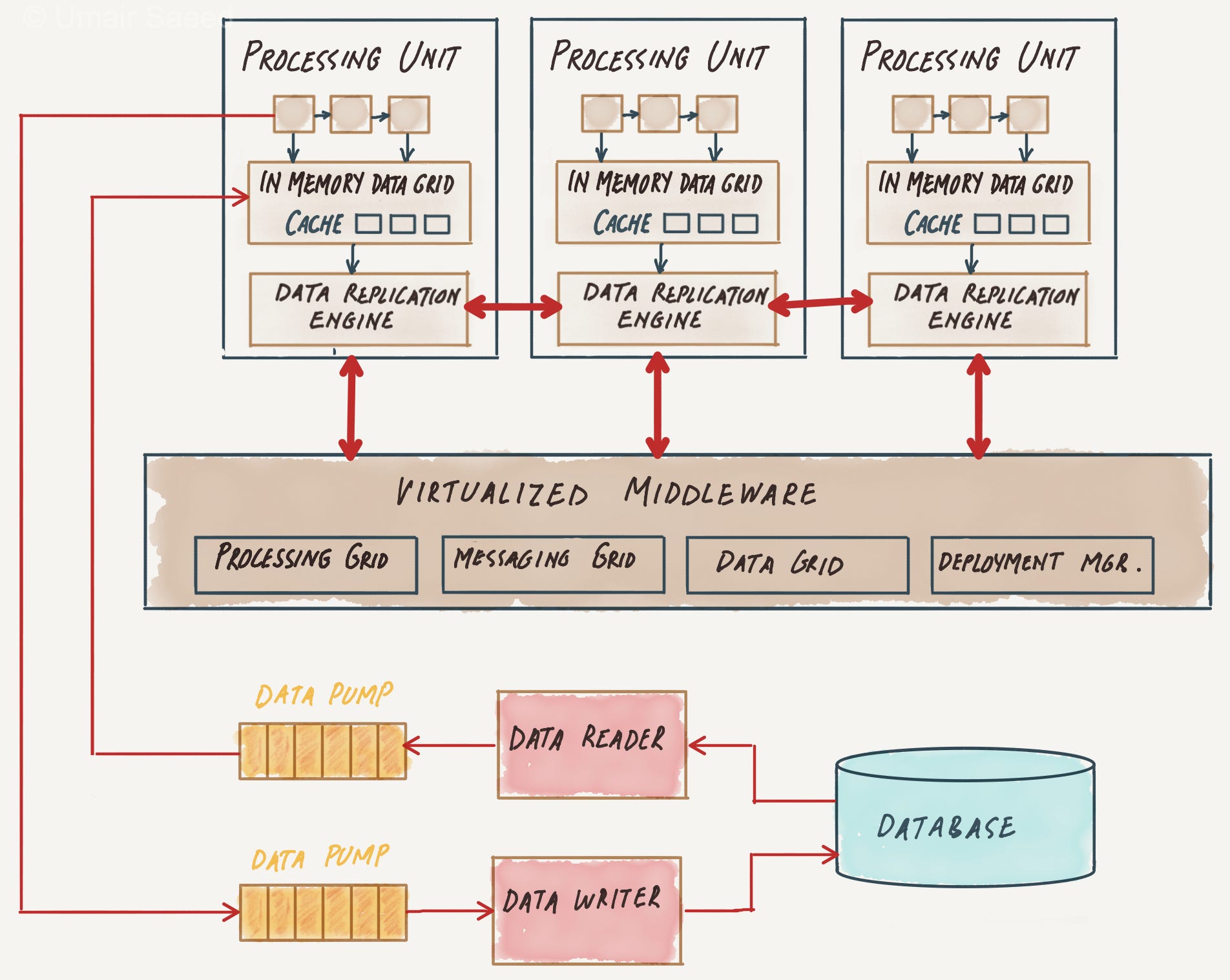
Essentially, in SBA applications are built out of a set of self-sufficient units, known as processing-units (PU). These units are independent of each other, so that the application can scale by adding more units.
“At its core, SBA is a software architecture design aimed at achieving linear scalability for high-performance applications and systems. This architecture accomplishes scalability by distributing both processing and storage across multiple servers, effectively creating a “shared nothing” system. The term “space-based” is derived from the concept of tuple space, a form of shared memory where all data resides and is accessible to every processing unit.”
The sharing of a common memory allows for a strong fault tolerance (in the PUs) and data availability. Since data is stored in memory, across multiple nodes, it offers fast access and reduces the need for expensive disk I/O. For applications that require high scalability, fault tolerance, and low latency, such as real-time data processing, analytics, and ML modeling, the Space Based Data Hub is a particularly powerful platform.
The main components of Space Based Architectures-
SBAs are built from the following components
Processing Units (PU): The part that will perform the business logic and has all the data required to execute. Since they rely on shared data spaces, PUs can be replicated, allowing for efficient load balancing (the work is spread evenly across PUs) and failover (if a PU fails, others can take over its tasks).

Virtualized Middleware: This layer handles the shared infrastructure concerns for this architecture. It has the following components:
The Data grid: The backbone this architecture. A given request can be assigned to any of the available processing units, so each PU must contain the same data in its in-memory grid. The data grid is responsible for synchronizing data between the processing units by building the Tuple space (a repository, where processes can add, withdraw or read tuples by means of atomic operations).
The Messaging grid: Handles the flow of incoming transactions as well as the communication between services
The processing grid: Parallel processing component based on the master/worker pattern (also known as a blackboard pattern) that enables parallel processing of events among different services.
Deployment manager: Manages the startup and shutdown of the PUs, starts up new PUs to handle any additional load, and shuts down PUs once they are no longer needed.
Data Pumps: Data pumps are responsible for marshaling data between the database and the processing units.
Data Writers and Readers: Names are self-explainatory

Performance of SBA vs Architectures-
For a good overview, take a look at the table below-

Let’s do a deeper dive into the pros and cons.
Problems it solves:
Scalability: Adding more processing units allows the system to handle exponentially more data without performance bottlenecks.
Performance: Direct access to shared data in memory provides low-latency, high-throughput communication.
Fault tolerance: Data remains accessible even if individual components fail due to redundancy within the space.
Flexibility: Processing units can be added or removed dynamically, adapting to changing needs.
Limitations to consider:
Complexity: Design and implementation require deep understanding of data flow and concurrency. The key to implementing SBA properly seems to be in breaking down the process into functional units that can be turned into PUs.
Debugging: Troubleshooting issues within the shared space can be challenging.
Security: Ensuring data integrity and access control within the shared space is crucial.
Limited adoption: The concept seems to be very unpopular, and mature tooling and best practices are still evolving. I tried to look into case-studies of software firms using it, but couldn’t find any direct sources (only indirect claims where a blog post claims that some other company used it).
SBA and AI
While researching this piece, I thought about some interesting overlaps between AI and SBA. Here are some ways I would think about using SAB/SBA adjacent principles to improve your AI:
Federated Learning: FL is a way to improve ML Security, Efficiency, and Privacy all in one. Instead of sending data back to the server of an AI Application, we send, the AI Model updates. The server aggregates the updates from multiple devices (as appropriate), and then sends the models updates back to the devices. It’s one of Amazon’s mainstays, and we covered it in our deep five- How Amazon makes Machine Learning Trustworthy

Real-time AI at the Edge: SBA's low-latency communication can facilitate real-time AI processing at the edge of networks, enabling applications like autonomous vehicles or predictive maintenance in IoT scenarios. A few years ago, I briefly worked with someone looking to build automated robots that can help in detecting survives in disasters. I can see this being super useful there (especially the idea of a tuple space). Also, here is my obligatory plug for how cool and universal self-organizing AI can be because I’m definitely seeing parallels here
Supply Chains: Another idea that this might work well in. You could load the supply chain into a shared space, and let clusters of PUs handle different regions. By only having an AI focus on one area, you would keep your AI costs down, and would be able to quickly identify data drift in various regions (you would be able to see if there is data from one region/time that doesn’t match with the protocols of your analysis)
Improved Explainability and Debugging: The idea of splitting the decision system into smaller units can be really useful for a deeper level insight into your system (what sub-problem is your AI messing up at).

Something tells me that Mixture of Experts might benefit a lot from an approach inspired by SBA. For multi-modal tasks, imagine having access to a shared pretraining space + input, and then using a gating protocol to call specialized PUs. Here you’d combine the inherent expressivity of multi-modal processing with the performance + cost of specialized setups. I’m a bit fuzzy on details, but if one of you applied researchers has some money + a troop of PhD grunts lying around, this would be a very cool investigation.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.

Save the time, energy, and money you would burn by going through all those videos, courses, products, and ‘coaches’ and easily find all your needs met in one place at ‘Tech Made Simple’! Stay ahead of the curve in AI, software engineering, and the tech industry with expert insights, tips, and resources. 20% off for new subscribers by clicking this link. Subscribe now and simplify your tech journey!
Using this discount will drop the prices-
800 INR (10 USD) → 640 INR (8 USD) per Month
8000 INR (100 USD) → 6400INR (80 USD) per year (533 INR /month)
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819