
Understanding the Different Types of Transformers in AI [Math Mondays]
Understanding the biggest neural network in Deep Learning

Hey, it’s your favorite cult leader here 🐱👤
Mondays are dedicated to theoretical concepts. We’ll cover ideas in Computer Science💻💻, math, software engineering, and much more. Use these days to strengthen your grip on the fundamentals and 10x your skills 🚀🚀.
To get access to all the articles and support my crippling chocolate milk addiction, consider subscribing if you haven’t already!
p.s. you can learn more about the paid plan here. To learn how you can get this newsletter for free, make sure you read till the end (after the poll).
Deep learning with transformers has revolutionized the field of machine learning, offering various models with distinct features and capabilities. While factors like the number of parameters, activation functions, architectural nuances, context sizes, pretraining data corpus, and languages used in training differentiate these models, one often overlooked aspect that can significantly impact their performance is the training process. In this article, we will delve into the three broad categories of transformer models based on their training methodologies: GPT-like (auto-regressive), BERT-like (auto-encoding), and BART/T5-like (sequence-to-sequence).
Ultimately, understanding the differences in these models and then leveraging them for your personal needs is a must. Too many people have been trying to shove GPT-4 into every language-based use case, regardless of whether it would be appropriate. Through this article, you will have a better understanding of the various types of Transformers, and when each would be most useful.

Sequence-to-Sequence Models:
Sequence-to-sequence models are the OG Transformers. These were introduced in the original Transformer paper, all the way back. Sequence to Sequence Transformer models adopt a relatively straightforward approach by embedding an entire sequence into a higher dimension, which is then decoded by a decoder. These were primarily designed for translation tasks, due to their excellence at mapping sequences between languages.
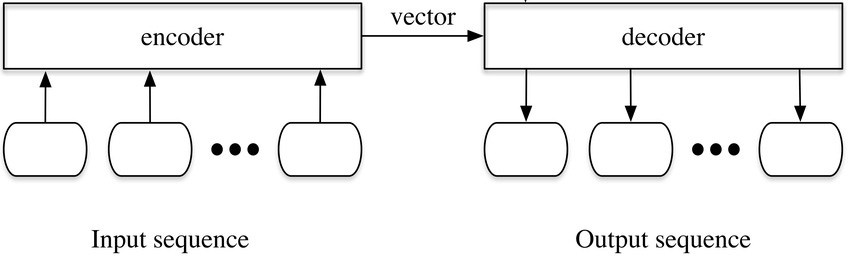
Say we want to translate from English to Hindi, we use the following steps-
Translate the English Sentence into an Embedding using the Encoder. ( Transform “ My name is Devansh” to “Gook Grak”).
Use a decoder designed to take the embedding and convert into a Hindi sentence. (Translate “Grook Grak” to “Mera naam Devansh hai”).
BOOM!
With these architectures, the focus is on taking and mapping sequences to each other. This makes them ideal for translation-related tasks. The use of the encoder and decoder blocks separately also brings another huge advantage into play- this approach can be scaled with newer languages relatively simply. To add a new language, all we need to do is change the encoders and decoders to and from the Embedding Language to the language we want to translate to/from.
These models are great, but what happens when we get to text generation? In such cases, we might not always have a complete sequence we are mapping to/from. The sequences might not be a perfect match (which would hold true for both very long and short sequences). This is where the next kind of Transformer architecture comes into play.
Autoregressive Models
Autoregressive models, popularized by GPT (Generative Pre-trained Transformer), leverage the prior tokens to predict the next token iteratively. They employ probabilistic inference to generate text, relying heavily on the decoder component of the transformer. Unlike sequence-to-sequence models, autoregressive models don’t require an explicit input sequence and are suitable for text generation tasks. They have gained immense popularity and exhibit versatility with fine-tuning, making them valuable for various applications, especially in business contexts.
Auto Regression is common in more than just Transformers. Tasks like Time Series Forecasting are very autoregressive in their nature. AR Transformers show some great versatility with fine-tuning, which is a huge plus with business bros.
The problem with Autoregressors is that the models don’t really have to understand the underlying text to generate it. This is one of the problems with text generated from AR models- while it looks structurally okay, it isn’t very reliable (the much-discussed Hallucinations). This shows up for ‘simpler’ cases, such as text summaries- which are often still filled with falsehoods (PSA- GPT based summary tools are a really stupid idea). Fortunately, for tasks that require advanced language understanding, we can use the next kind of Transformer architecture.
Autoencoding Models:
If we have transformers that focus extensively on the decoder, it shouldn’t surprise you that we also have transformers that work heavily on the encoding side of things. This is where autoencoding models come into play. Autoencoding models are specifically oriented toward language understanding and classification tasks, aiming to capture meaningful representations of input data in their encoded form.
The training process of autoencoding models often involves bidirectionality, which means they consider both the forward and backward context of the input sequence. By leveraging bidirectional encoding, these models can capture dependencies and relationships within the text more effectively. Additionally, autoencoders employ masking techniques to deliberately hide or corrupt certain parts of the input during training. This process forces the model to learn robust features and develop the ability to reconstruct and identify missing or corrupted information.
Notable Autoencoders include the BERT family, which became mainstays in many classifications and summarization-oriented tasks (especially in the finance and legal space). You should not overlook these when it comes to your uses. I’ve seen great use of these in the information retrieval space, where we can ask AI Models to answer questions about a specific knowledge base (pdf, excel etc).
Hopefully, you now have a better understanding of the various kinds of transformers and how they differ. Deep learning with transformers encompasses a diverse range of models, each with its unique training methodology and purpose. Sequence-to-sequence models excel at mapping sequences between languages, autoregressive models are powerful for text generation, and autoencoding models focus on language understanding and classification. Understanding the different types of transformers and their training processes can guide researchers, practitioners, and enthusiasts in selecting the most suitable model for their specific use cases. As the field of artificial intelligence continues to evolve, advancements in transformer models promise exciting developments in natural language processing and artificial intelligence as a whole.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. If you refer people using the button below, you will get many cool benefits such as magic swords, dragons, and complimentary premium subscriptions
Save the time, energy, and money you would burn by going through all those videos, courses, products, and ‘coaches’ and easily find all your needs met in one place at ‘Tech Made Simple’! Stay ahead of the curve in AI, software engineering, and the tech industry with expert insights, tips, and resources. 20% off for new subscribers by clicking this link. Subscribe now and simplify your tech journey!

Using this discount will drop the prices-
800 INR (10 USD) → 640 INR (8 USD) per Month
8000 INR (100 USD) → 6400INR (80 USD) per year (533 INR /month)
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
Good write-up, thanks for sharing. I would bring a bit of nuance here. These are more different applications of Transformers than different types of Transformers. Bert encoder is an auto-encoder, Bert decoder is auto-regressive. Auto-encoder are used to map their input to some latent representations (generally embeddings), auto-regressive decoder are used to generate sequences of words and sentences.